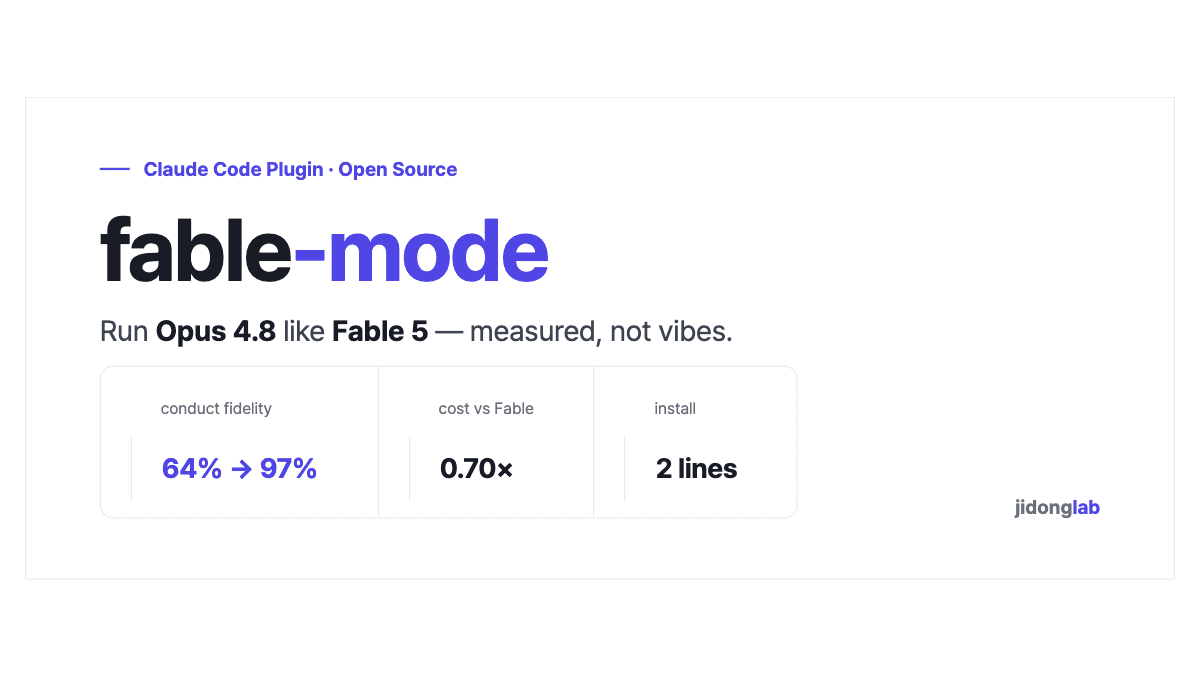
Fable 5 costs exactly 2× Opus 4.8. The measurable difference between them turned out to be mostly — a system prompt.
I ported the portable half of that difference into a Claude Code plugin and ran it against the real thing. Conduct fidelity climbed from 64% to 97%, and the same work landed at roughly 0.70× what it would have cost on Fable 5.
Here is the write-up, including the two bugs that almost shipped.
Weights or manners — which half actually differs?
When people compare Fable 5 and Opus 4.8, they argue about intelligence. After watching both models work the same tasks, I think most of the day-to-day gap is manners, not brains.
Two things separate the models. One is the weights — the reasoning itself — and that is not portable; you cannot copy it out. The other is a set of communication norms that get injected into Fable's system prompt: lead with the conclusion, finish the task instead of asking, verify before you claim, and never leak your own scaffolding. That half is just text, and text moves.
The pricing makes the bet worth taking. Fable 5 runs $10 per million input tokens and $50 output; Opus 4.8 is exactly half, at $5 and $25. If most of what I like about Fable is a prompt, I should be able to rent Opus at half price and paste the manners back in.
How do three hooks turn Opus into a Fable impersonator?
The whole port is three Claude Code hooks, one output style, and a /fable-mode skill. The hooks carry the weight.
# SessionStart: detect model, arm only for Opus
if model.startswith("opus"): inject(conduct_norms)
# every turn: re-assert norms so they survive context drift
prepend(conduct_norms)
# Stop: self-check once, rewrite the reply, never leak the rubric
review = grade(reply, rubric) # 6 dimensions
reply = rewrite(reply, review) # user-facing only
The SessionStart hook checks the model and arms only when it sees Opus — running the norms on top of Fable would just be double-dosing. Every turn re-injects them, because a long session drifts and the original instructions sink out of the model's attention. The Stop hook grades the draft reply against a six-point rubric, rewrites it, and — this is the part that took two tries — strips every trace of the rubric before you see the answer.
Did it actually behave differently?
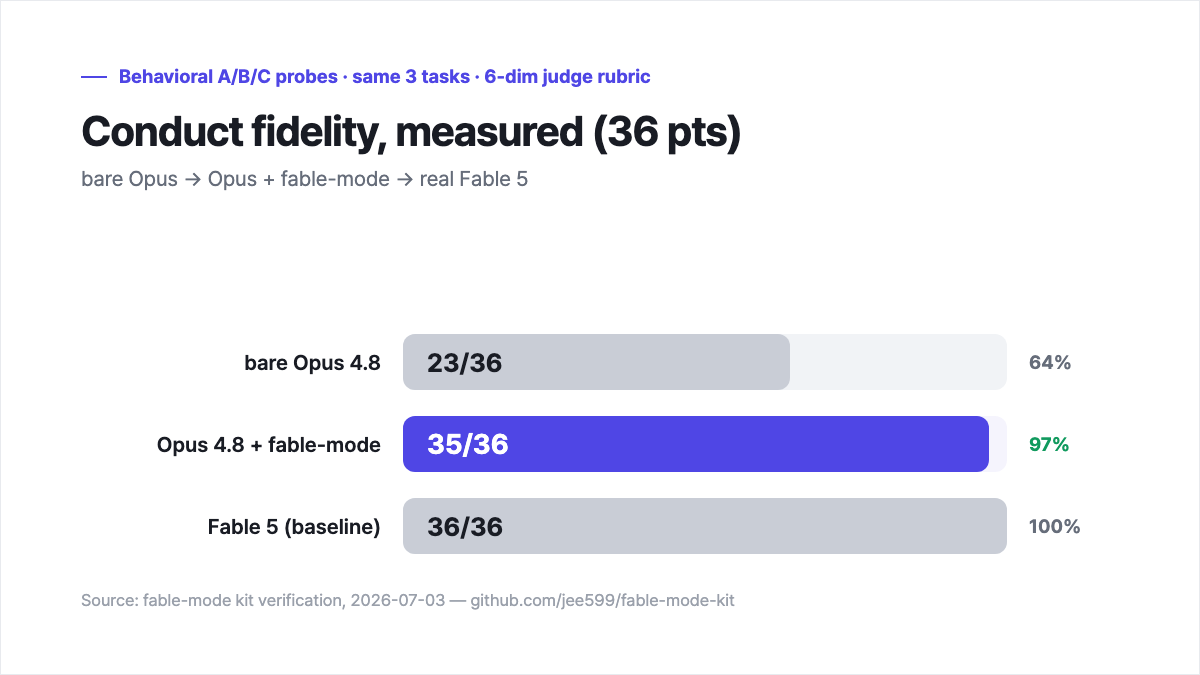
I ran three tasks under three conditions. A was vanilla Opus 4.8, B was Opus with the kit, and C was Fable 5. The tasks were chosen to bait bad manners: a diagnosis-only request, an implementation task where I never asked for verification, and a deliberately vague instruction. A separate judge model scored each run across six dimensions — conclusion-first, completeness, autonomy, verification, discipline, and no-leak — for 36 points total.
The debugging task was the cleanest tell. I asked vanilla Opus "why does this bug happen?" — a question, not a work order. It silently edited the file and declared the fix worked, without ever running the code. Six out of twelve. With the kit, the same model diagnosed the cause, left the file untouched, and backed its claim by actually executing. Twelve out of twelve.
The vague task was worse. "Clean up the logs," I said, deliberately giving it nothing to go on. Vanilla Opus investigated, then stopped and asked "which way would you like to do this?" — the single most annoying failure mode, the work handed straight back to me. Five out of twelve. The kit picked a safe default on its own: archive and gzip, non-destructive, executed and verified, holding only the irreversible deletion for me to approve. Twelve out of twelve.
| Condition | Score | % |
|---|---|---|
| A — vanilla Opus 4.8 | 23 / 36 | 64% |
| B — Opus 4.8 + fable-mode | 35 / 36 | 97% |
| C — Fable 5 | 36 / 36 | 100% |
 Measured A/B/C — Source: jidonglab
Measured A/B/C — Source: jidonglab
The two bugs, and what it actually costs
Two failures during development did more for my confidence in these numbers than the numbers themselves.
The first was identity contamination. I told Opus to "output only the word ok." It replied "Fable." The re-injected norms had bled into the model's sense of who it was. I added an explicit identity clause, and on re-measure it answered "I am Opus 4.8," correctly.
The second was a self-check leak. The Stop hook's rubric wording was surfacing verbatim in the final answer — the model was narrating its own grading out loud. I rewrote the instruction to forbid meta-commentary and keep only the user-facing conclusion. On re-run, zero leaks.
The manners are not free in tokens either. Re-injecting norms every turn and self-checking at the end pushed usage to about 1.41× a vanilla run. But Opus is half Fable's price, so 1.41 × 0.5 lands the same task at roughly 0.70× the cost of Fable — 71 to 78 percent across my runs.
Now the honest part. The 97% is a conduct score, not an intelligence score, and it comes from three tasks run once each. It says nothing about entangled, single-pass reasoning or long autonomous runs, where a third-party estimate still puts Opus 5 to 11 points behind Fable on benchmarks — an estimate, not my measurement. For reviews and audits I close that gap with multi-agent fan-out and adversarial verification, at 1 to 2.5× the cost; for high-risk calls I keep an N-attempt vote and a human gate. The plugin buys manners, not a smarter model.
Install is two lines inside Claude Code: run /plugin marketplace add jee599/fable-mode-kit, then /plugin install fable-mode@jidonglab. The hooks, output style, and full rubric live in the fable-mode-kit repo.
Sources: fable-mode-kit on GitHub · Claude Code documentation
The expensive model wasn't twice as smart. It was twice as disciplined — and discipline is just text you can move.