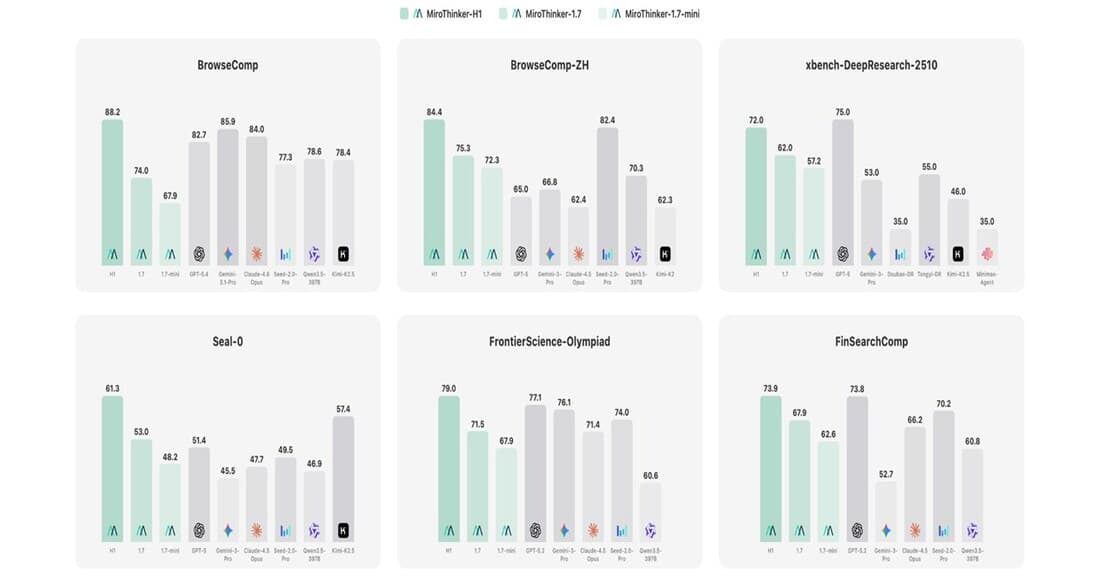
88.2. A Startup Just Beat Every Big Tech AI Model.
On March 16, Redwood City startup MiroMind unveiled MiroThinker-H1. On BrowseComp — the benchmark measuring AI's ability to conduct complex web research — it scored 88.2, surpassing GPT-5.4 (82.7), Claude-4.6-Opus (84.0), and Gemini 3.1 Pro (85.9).
This isn't just a leaderboard shuffle. It challenges the fundamental assumption that bigger models with more reasoning tokens always win. MiroThinker-H1 won by verifying each reasoning step rather than scaling the number of steps.
Background: Why BrowseComp Matters
BrowseComp, released by OpenAI in 2025, evaluates AI's ability to perform complex multi-step web research: navigating multiple pages, resolving conflicting information, and synthesizing conclusions. These are tasks that take human researchers 30-60 minutes.
| Timeline | Model | BrowseComp Score | Approach |
|---|---|---|---|
| Early 2025 | GPT-4o + search | ~40s | Simple search + summary |
| Mid 2025 | Claude 3.5 Opus | ~65 | Multi-step reasoning |
| March 2026 | GPT-5.4 | 82.7 | Massive reasoning + Tool Search |
| March 2026 | Claude-4.6-Opus | 84.0 | Deep web exploration |
| March 2026 | Gemini 3.1 Pro | 85.9 | Native Google Search |
| March 2026 | MiroThinker-H1 | 88.2 | Verification-centric dual layer |
The field went from 40s to 88.2 in one year. And a startup sits at the top.
Core Technology: Dual-Layer Verification
The prevailing approach to improving AI reasoning has been twofold: scale model size (more parameters) and scale reasoning tokens (longer Chain-of-Thought). The problem: longer reasoning chains amplify errors. One wrong step in a 100-step chain corrupts everything downstream.
MiroMind calls their alternative Effective Interaction Scaling — improving the quality of each reasoning step rather than the quantity. MiroThinker-H1's architecture centers on a Dual-Layer Verification System:
Layer 1 — Internal Verifier: The model checks each reasoning step in real-time during inference. Unlike conventional models that verify only after completion, MiroThinker validates as it reasons.
Layer 2 — External Verifier: After reasoning completes, a separate verification module cross-checks conclusions against independent sources, performing reverse validation ("if this conclusion is true, these additional facts must also be true").
This approach is more efficient because catching wrong reasoning paths early prevents wasted computation. Verifying every 10 steps beats completing 100 wrong steps and restarting.
| Approach | Representative | Strategy | Strength | Weakness |
|---|---|---|---|---|
| Scale model size | GPT-5.4, Claude 4.6 | More parameters | Versatility | Cost, energy |
| Scale reasoning | o3, DeepThink | Longer CoT | Complex problems | Error snowball |
| Verification-centric | MiroThinker-H1 | Real-time step verification | Accuracy, efficiency | Versatility unproven |
Multilingual Performance
MiroThinker-H1 also tops BrowseComp-ZH (Chinese) at 84.4, beating ByteDance's Seed-2.0-Pro (82.4) and GPT-5 (65.0), demonstrating cross-language research capability.
The Broader AI Verification Trend
MiroThinker-H1 fits into a growing movement in AI research: the shift from "scale everything" to "verify everything." Several parallel developments signal this trend:
**Constitutional AI **(Anthropic) — Uses AI to check AI outputs against a set of principles. This is verification at the alignment level.
**Process Reward Models **(OpenAI) — Rewards each step of reasoning, not just the final answer. This is verification at the training level.
MiroThinker's dual-layer approach — Verifies each reasoning step during inference in real-time. This is verification at the deployment level.
The convergence is clear: the next frontier in AI isn't just making models smarter, but making them reliably correct. In a world where AI agents are being deployed for real tasks (financial analysis, legal research, medical diagnosis), a model that's right 88% of the time is dramatically more valuable than one that's right 85% of the time — the remaining errors in high-stakes domains can be catastrophic.
Who Is MiroMind?
MiroMind is a relatively unknown Redwood City startup that has been operating in stealth until this announcement. The team appears to come from a deep research background, with their arXiv paper demonstrating rigorous academic methodology. Their GitHub repository is open-source, suggesting a strategy similar to Meta's Llama: build credibility through open research before commercializing.
The fact that a small, previously unknown team can top a major benchmark against GPT-5.4, Claude 4.6, and Gemini 3.1 is itself a powerful statement about the current state of AI research. You don't need Google-scale compute to make meaningful contributions — you need the right architectural insight.
What This Means
"Bigger" isn't always better. MiroThinker-H1 proves that a relatively simple mechanism — verification integrated into reasoning — can beat trillion-dollar-backed models. This opens the door for resource-constrained teams to compete on accuracy.
Agent reliability depends on verification. For high-stakes domains like finance, law, and healthcare, "not being wrong" matters more than "being fast." Verification-centric architectures are better suited for these applications.
The approach is open. MiroMind published their paper on arXiv and released code on GitHub, enabling the broader research community to build on verification-centric methods.
Limitations
BrowseComp #1 doesn't mean "best AI overall." Performance on coding (SWE-bench), math (MATH), and general reasoning (MMLU) benchmarks remains undisclosed. The dual verification system also adds computational overhead that may limit real-time applications. And being #1 on a single benchmark doesn't guarantee commercial success — many top-performing research models never find product-market fit. Still, the verification-centric approach is compelling enough that we expect major labs to integrate similar mechanisms into their next-generation models.


