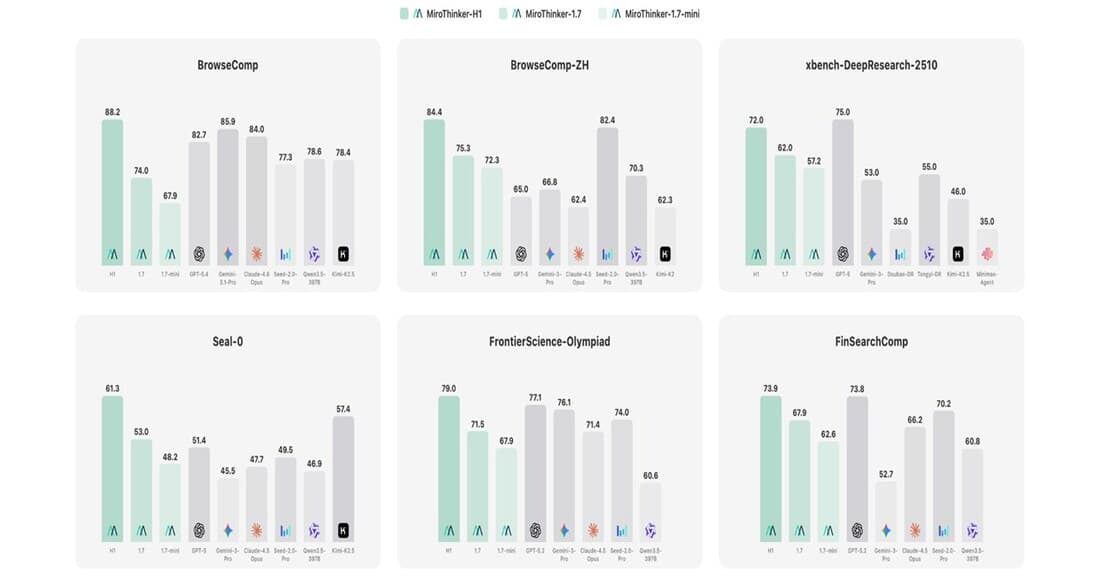
88.2점. 빅테크 전부를 이긴 스타트업.
3월 16일, 레드우드시티의 스타트업 MiroMind가 MiroThinker-H1을 공개했어. BrowseComp(AI가 웹에서 복잡한 정보를 찾아 추론하는 벤치마크)에서 88.2점을 기록하며 GPT-5.4(82.7), Claude-4.6-Opus(84.0), Gemini 3.1 Pro(85.9)를 전부 넘겼어.
이건 단순한 벤치마크 1위가 아니야. AI 연구의 방향성 자체에 대한 질문을 던지는 결과야. "더 크고 더 많이 추론하는" 방식이 아니라 각 단계가 틀리지 않도록 검증하는 방식이 이긴 거니까.
배경: BrowseComp란 무엇이고 왜 중요한가
BrowseComp 벤치마크의 탄생
BrowseComp는 OpenAI가 2025년에 공개한 벤치마크야. AI가 실제 웹 환경에서 복잡한 리서치 태스크를 수행할 수 있는지를 평가해. 단순한 질의응답이 아니라, 여러 웹페이지를 오가며 정보를 수집하고, 상충되는 정보를 판단하고, 최종 결론을 도출하는 능력을 측정해.
예를 들어 "2024년 미국에서 가장 많이 인용된 AI 논문의 주저자가 현재 재직 중인 대학의 설립 연도는?"처럼 여러 단계의 추론과 웹 검색이 필요한 문제들이야. 인간 리서처도 30분–1시간이 걸리는 작업을 AI가 몇 분 안에 해야 해.
AI 리서치 에이전트의 진화
| 시기 | 모델/제품 | BrowseComp 점수 | 접근 방식 |
|---|---|---|---|
| 2025년 초 | GPT-4o + 웹 검색 | 약 40점대 | 단순 검색 + 요약 |
| 2025년 중반 | Claude 3.5 Opus | 약 65점대 | 멀티스텝 추론 |
| 2026년 3월 | GPT-5.4 | 82.7 | 대규모 추론 + Tool Search |
| 2026년 3월 | Claude-4.6-Opus | 84.0 | 심층 웹 탐색 |
| 2026년 3월 | Gemini 3.1 Pro | 85.9 | Google Search 네이티브 통합 |
| 2026년 3월 | MiroThinker-H1 | 88.2 | 검증 중심 이중 레이어 |
1년 만에 40점대에서 88점대로 올라온 거야. 그리고 그 정상에 빅테크가 아닌 스타트업이 서 있어.
핵심 기술: 검증 중심(Verification-Centric) 아키텍처
기존 방식의 한계 — "더 많이 생각하면 더 정확할까?"
지금까지 AI 추론 성능을 높이는 주된 방법은 두 가지였어:
- 모델 크기 키우기: 파라미터를 늘려서 더 많은 지식을 담기
- 추론 토큰 늘리기: Chain-of-Thought(CoT)를 더 길게 해서 더 많이 "생각"하게 하기
OpenAI의 o1, o3 시리즈가 이 접근의 대표야. 문제는 추론을 길게 할수록 중간에 한 번 틀리면 전체가 틀어진다는 거야. 100단계 추론에서 1단계가 잘못되면 나머지 99단계가 아무리 정교해도 결론이 틀려. 이걸 "추론 오류의 눈덩이 효과"라고 불러.
MiroThinker의 해법 — Effective Interaction Scaling
MiroMind은 완전히 다른 접근을 했어. MiroThinker의 핵심 철학은 "추론의 신뢰성은 궁극적으로 시스템이 자신의 추론 과정을 검토하는 능력에 달려있다"는 거야.
MiroThinker-H1의 핵심은 이중 레이어 검증 시스템(Dual-Layer Verification System)이야:
레이어 1 — 내부 검증기(Internal Verifier): 모델이 추론의 각 단계에서 "이 추론이 맞는가?"를 스스로 점검해. 기존 모델들은 추론이 끝난 후에야 결과를 검증하지만, MiroThinker는 추론 중에 실시간으로 각 단계를 검증해.
레이어 2 — 외부 검증기(External Verifier): 전체 추론 과정이 끝난 후, 별도의 검증 모듈이 결론의 일관성과 사실 정확성을 재검토해. 웹에서 추가 소스를 찾아 교차 확인하는 과정이 포함돼.
이걸 MiroMind은 Effective Interaction Scaling이라고 불러. 추론의 양(quantity)을 늘리는 게 아니라 추론의 질(quality)을 높이는 방식이야. 이건 기존의 "더 크게, 더 많이" 패러다임과 근본적으로 다른 접근이야.
기존 패러다임과의 비교
| 접근 방식 | 대표 모델 | 핵심 전략 | 장점 | 단점 |
|---|---|---|---|---|
| 모델 크기 확장 | GPT-5.4, Claude 4.6 | 더 많은 파라미터 | 범용성 | 비용, 에너지 |
| 추론 토큰 확장 | o3, DeepThink | 더 긴 CoT | 복잡한 문제 해결 | 오류 눈덩이, 비용 |
| 검증 중심 | MiroThinker-H1 | 각 단계 실시간 검증 | 정확도, 효율성 | 범용성 미검증 |
BrowseComp-ZH에서도 1위 — 다국어 능력까지
MiroThinker-H1은 영어 BrowseComp뿐 아니라 중국어 버전인 BrowseComp-ZH에서도 84.4점으로 1위를 기록했어. ByteDance의 Seed-2.0-Pro(82.4)와 GPT-5(65.0)를 모두 상회해. 다국어 웹 리서치 능력까지 검증된 거야.
| 벤치마크 | MiroThinker-H1 | Gemini 3.1 Pro | Claude 4.6 Opus | GPT-5.4 |
|---|---|---|---|---|
| BrowseComp (EN) | 88.2 | 85.9 | 84.0 | 82.7 |
| BrowseComp-ZH (CN) | 84.4 | — | — | 65.0 (GPT-5) |
MiroMind은 어떤 회사인가
MiroMind은 레드우드시티(캘리포니아)에 본사를 둔 AI 스타트업이야. OpenAI, Google DeepMind, Meta FAIR 출신의 연구원들이 설립했어. 회사 이름의 "Miro"는 "Mirror"에서 왔고, "인간 지능을 반영(mirror)하고 연결(connect)하는 AI"를 만든다는 비전이야.
팀 규모나 총 투자 금액은 아직 공개되지 않았지만, arXiv에 논문을 공개하고 GitHub에 코드를 오픈소스로 공개하는 등 학술 커뮤니티와 적극적으로 소통하고 있어. MiroThinker 자체도 GitHub에서 공개되어 있어.
기술 심층 분석: Effective Interaction Scaling이 작동하는 방식
MiroThinker-H1의 논문(arXiv:2603.15726)에 따르면, 이중 검증 시스템은 구체적으로 이렇게 작동해:
1단계 — 쿼리 분해(Query Decomposition): 복잡한 리서치 질문을 여러 개의 하위 질문으로 분해해. "2024년 미국에서 가장 많이 인용된 AI 논문의 주저자가 현재 재직 중인 대학의 설립 연도는?"이라는 질문을 "가장 많이 인용된 AI 논문 찾기 → 주저자 식별 → 현재 소속 대학 확인 → 대학 설립 연도 검색"으로 분해하는 거야.
2단계 — 검증된 검색(Verified Search): 각 하위 질문에 대해 웹 검색을 수행하고, 검색 결과의 신뢰성을 자동으로 평가해. 위키피디아, 공식 사이트, 학술 데이터베이스 같은 신뢰도 높은 소스를 우선하고, 블로그나 포럼 같은 저신뢰 소스는 교차 검증이 필요한 것으로 분류해.
3단계 — 단계별 내부 검증(Step-wise Internal Verification): 각 추론 단계가 이전 단계와 논리적으로 일관되는지, 수집한 데이터와 모순이 없는지를 실시간으로 점검해. 모순이 발견되면 해당 단계를 폐기하고 다른 경로로 재추론해.
4단계 — 최종 외부 검증(Final External Verification): 모든 추론이 완료된 후, 결론을 독립적인 소스로 교차 확인해. "이 결론이 맞다면, 이런 부가적 사실도 참이어야 한다"는 식의 역방향 검증을 수행해.
이 4단계 과정이 MiroThinker의 "Effective Interaction Scaling"이야. 추론의 단계 수를 늘리는 게 아니라, 각 단계의 신뢰도를 높여서 전체 추론의 정확도를 끌어올리는 방식이야.
왜 이 방식이 더 효율적인가
기존의 추론 확장(reasoning scaling)은 문제 하나에 수천–수만 토큰을 사용해. o3 같은 모델은 단일 수학 문제에 10만 토큰 이상을 쓰기도 해. MiroThinker는 검증 단계를 추가하지만, 잘못된 추론 경로를 빨리 차단하기 때문에 총 토큰 사용량이 오히려 적을 수 있어. 잘못된 100단계를 하고 다시 시작하는 것보다, 10단계마다 검증해서 잘못된 방향을 바로잡는 게 더 효율적이니까.
개발자와 AI 연구자에게 주는 의미
1. "더 크게"가 항상 답은 아니야
MiroThinker-H1의 성공은 "모델을 키우고 추론을 늘리는" 기존 패러다임에 대한 강력한 반증이야. 검증이라는 상대적으로 단순한 메커니즘을 추론 과정에 통합하는 것만으로도 수조 원을 투자한 빅테크의 거대 모델을 이길 수 있다는 걸 보여줬어.
2. 에이전트 신뢰성의 핵심은 검증
AI 에이전트가 실제 업무에 투입되려면 "정확한 답"보다 "틀리지 않는 답"이 더 중요할 수 있어. 금융 리서치, 법률 검토, 의료 진단 같은 분야에서는 한 번의 오류가 치명적이니까. MiroThinker의 검증 중심 접근은 이런 고위험 영역에서 AI 에이전트의 실용화를 앞당길 수 있어.
3. 오픈소스 접근이 혁신을 가속화
MiroThinker가 GitHub에 코드를 공개하고 arXiv에 논문을 올린 건, 다른 연구자들이 검증 중심 접근을 발전시킬 수 있게 한다는 뜻이야. 빅테크가 점점 모델을 닫아가는 추세와 반대 방향이야.
4. 스타트업의 기회
BrowseComp 1위라는 결과는 MiroMind의 채용, 투자 유치, 기업 고객 확보에 강력한 신호가 될 거야. "빅테크의 모든 모델을 이긴 스타트업"이라는 이야기는 투자자들에게 매력적이니까.
산업별 적용 가능성
MiroThinker-H1의 검증 중심 접근은 특히 다음 산업에서 높은 가치를 가져:
| 산업 | 적용 시나리오 | 왜 검증이 중요한가 |
|---|---|---|
| 금융 | 투자 리서치, 규정 준수 검토 | 잘못된 데이터 하나가 수백만 달러 손실 |
| 법률 | 판례 검색, 계약서 검토 | 누락된 판례가 소송 패배로 직결 |
| 의료 | 임상 문헌 리서치, 약물 상호작용 | 잘못된 정보가 환자 안전 위협 |
| 저널리즘 | 팩트체크, 출처 검증 | 오보가 신뢰도와 법적 리스크 |
| 학술 연구 | 문헌 조사, 데이터 교차 검증 | 재현성 위기의 핵심 원인 |
이 모든 분야의 공통점은 "정확성이 속도보다 중요하다"는 거야. MiroThinker의 검증 시스템은 속도를 약간 희생하더라도 정확성을 극대화하는 방식이라, 이런 고위험 분야에 특히 적합해.
한계와 주의점
BrowseComp 1위가 곧 "최고의 AI"를 의미하진 않아. BrowseComp는 웹 리서치 특화 벤치마크이고, 코딩(SWE-bench), 수학(MATH), 범용 추론(MMLU) 같은 다른 벤치마크에서의 성능은 아직 미공개야. 또한 이중 검증 시스템은 추가 연산 비용을 수반하기 때문에, 실시간 응답이 필요한 서비스에서의 적용 가능성은 별도로 검증이 필요해.


