
GPQA 32% in 10 Hours -- HuggingFace's AI Intern Outperformed Claude Code
An open-source agent that automates the entire LLM post-training pipeline: lit scan, dataset discovery, training scripts, eval, and iteration. 6,800 stars, growing 260/day.

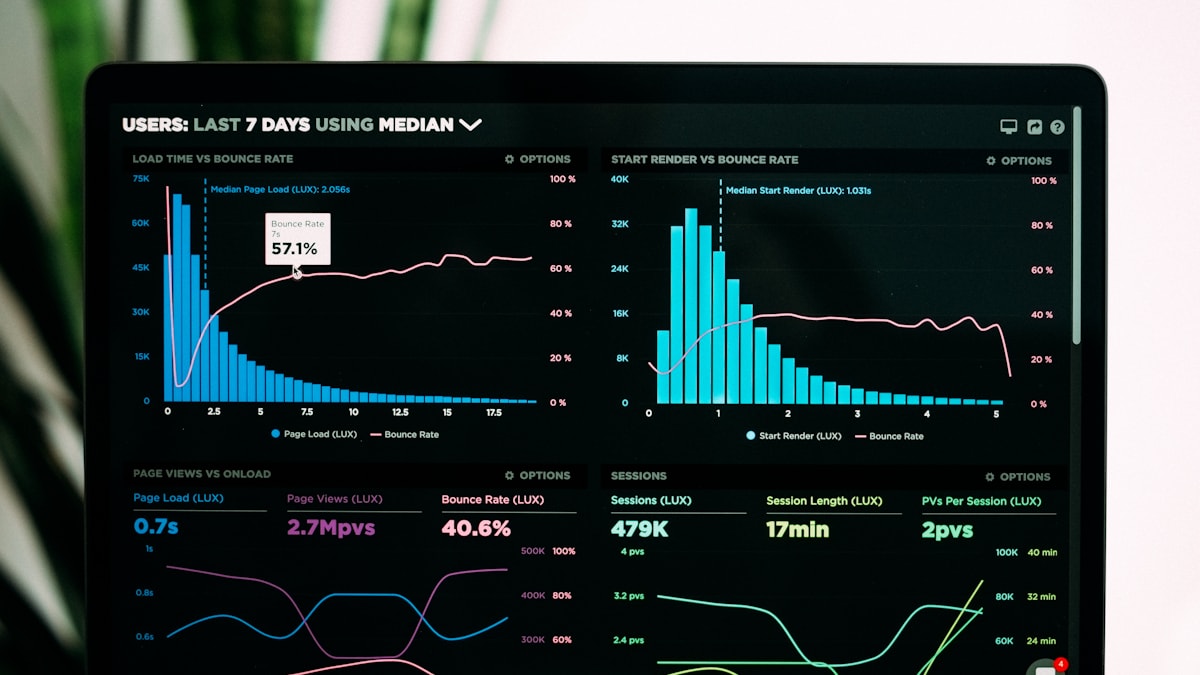
32% on a Benchmark Designed to Stump Experts
GPQA -- Graduate-Level Google-Proof Q&A -- is a benchmark of science questions hard enough that even domain experts can't just Google the answers. It's designed to test genuine reasoning ability.
HuggingFace's ml-intern agent scored 32% on it. Claude Code scored 22.99%. The agent ran for 10 hours with zero human intervention.
But the score isn't the real story. What matters is the scope of what ml-intern did: it searched papers, found relevant datasets, wrote training scripts, trained a model, evaluated the results, identified gaps, and iterated. The entire post-training pipeline, automated end to end.
What ml-intern Actually Does
 ml-intern's automated post-training pipeline
ml-intern's automated post-training pipeline
Think of it as an ML research intern that never sleeps. You give it a goal -- "improve scientific reasoning" -- and it executes:
- Literature Scan: Searches arXiv and Semantic Scholar for relevant papers, extracts key techniques
- Dataset Discovery: Finds training data on HuggingFace Hub, evaluates quality
- Training Script Generation: Writes fine-tuning code using TRL (Transformer Reinforcement Learning)
- Evaluation: Benchmarks the trained model and analyzes results
- Iteration: If results are lacking, repeats the cycle with improvements
A human researcher takes weeks to do this. ml-intern did it in 10 hours.
Tech Stack
- Framework: smolagents (HuggingFace's lightweight agent framework)
- Training: Transformers, TRL
- Data: Datasets library
- Language: Python
- License: Apache-2.0
Building on smolagents is significant. Unlike LangChain's heavy abstraction layers, smolagents uses a "code agent" approach -- it generates and executes code directly, giving it far more flexibility in tool usage.
Performance Context
| System | GPQA Score | Time | Human Input | Cost |
|---|---|---|---|---|
| ml-intern | 32% | 10 hours | None | GPU costs only |
| Claude Code | 22.99% | Manual | Full | API costs |
| Human ML researcher | Varies | Weeks | Full | Salary |
Fair warning: this isn't a perfectly apples-to-apples comparison. Claude Code is a general-purpose coding agent; ml-intern is specialized for ML post-training. But the point stands -- a specialized automated agent outperformed a general-purpose AI tool in its domain.
Competitor Landscape
| Project | Stars | Focus | Automation Scope | Framework |
|---|---|---|---|---|
| ml-intern | 6.8K | ML post-training | Papers-data-training-eval-iterate | smolagents |
| SWE-agent | 15K | Code bug fixing | Issue-patch-test | Custom |
| STORM | 9K | Paper writing | Research-outline-draft | Custom |
SWE-agent (Princeton NLP) automates code fixes. STORM (Stanford OVAL) automates paper writing. ml-intern automates the experiments themselves. Different lanes, minimal overlap.
Why It's Trending Now
 Climbing GitHub Trending at 260 stars/day
Climbing GitHub Trending at 260 stars/day
At 260 stars per day, ml-intern is punching well above its weight for a 6.8K-star project. A few reasons it's gaining traction.
The project targets an acute pain point: the repetitive grind of ML research. Reading papers, finding datasets, writing training code, tuning hyperparameters -- roughly 80% of this work is mechanical, not creative. ml-intern automates the mechanical parts.
It also benefits from deep HuggingFace ecosystem integration. Transformers, TRL, Datasets, Hub -- everything works natively. If you're already in the HuggingFace stack, adoption cost is near zero.
And the Product Hunt launch on April 23 (365 upvotes) gave it visibility beyond the typical GitHub audience. Running an open-source launch and a product launch simultaneously was a smart play.
Ecosystem Context
ml-intern signals the start of "AI training AI" becoming practical. Where Hermes Agent handles agent self-improvement and Google ADK handles deployment infrastructure, ml-intern carves out research automation as its own axis. The 2026 agent ecosystem is specializing fast.
The bigger implication is a shift in what ML researchers actually do. Less hyperparameter tuning and dataset curation, more setting research direction and interpreting results.
Getting Started
pip install ml-intern
ml-intern run --task "improve scientific reasoning"
One command kicks off the full pipeline. You'll need GPU access (A100 recommended minimum) and a HuggingFace Hub token configured.
Who Should Skip This
- If you only need inference, not training
- If you have no GPU access
- If you want fine-grained control over every training step (ml-intern is highly autonomous, making mid-run intervention difficult)
What's Next
 ml-intern development roadmap
ml-intern development roadmap
- Multi-GPU and multi-node training support
- Experiment tracking integration (Weights & Biases, MLflow)
- Automated paper draft generation
An agent that automates 80% of ML post-training. If this is the "intern" version, the "senior" version is going to be something else entirely.
References
관련 기사
An AI Intern That Runs Your Entire Post-Training Pipeline -- ml-intern on PH
HuggingFace's open-source agent automates lit scans, dataset discovery, training, eval, and iteration. 365 upvotes on Product Hunt. Free and Apache-2.0.

OpenClaw — Why a Local AI Assistant Hit 250K Stars on GitHub
No cloud, no data leaving your device. Connects 50+ platforms including WhatsApp, Telegram, Slack, and iMessage. A weekend project became one of the fastest-growing open-source repos in GitHub history.

95,600 Stars in 7 Weeks -- Nous Research Built an Agent That Improves Itself
Hermes Agent ships a reflection loop, trace-based RL fine-tuning, and multi-LLM routing out of the box. At 1,500 stars per day, it's the fastest-growing agent framework on GitHub.
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.