
ZenBrain -- Neuroscience-Inspired 7-Layer Memory That Gives LLM Agents Real Recall
While most agent memory systems still rely on system-engineering metaphors like VM paging and flat vector stores, ZenBrain borrows consolidation, reconsolidation, and forgetting from 15 neuroscience models to build 7 memory layers and 9 algorithms. Result: LoCoMo F1 +21.6%, temporal queries +176%, MemoryArena +19.5%.
+21.6 F1
Ask someone what they had for lunch yesterday and the answer comes fast. Ask about lunch on the second Tuesday of March and they stall. Human memory is not a flat database. The hippocampus holds short-term traces, sleep consolidates the important ones into cortex, and the amygdala fast-tags anything emotionally charged. This lifecycle of encoding, consolidation, retrieval, reconsolidation, and forgetting is what makes human recall both efficient and resilient over long time horizons.
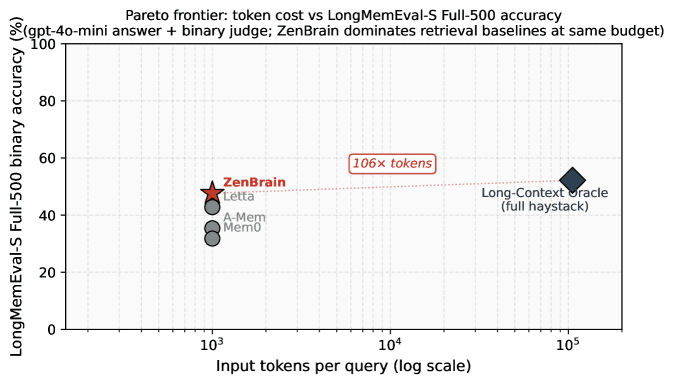
LLM agents have none of this. They stuff conversation logs into a vector DB, truncate when the token window overflows, or at best run a summarization pass before archiving. It is virtual-memory paging dressed up as memory. ZenBrain, a new paper from Alexander Bering at Zensation AI, flips this by importing 15 neuroscience models into a 7-layer, 9-algorithm memory architecture. On the LoCoMo benchmark it lifts F1 by 21.6 percent overall and 176 percent on temporal queries. On MemoryArena it gains 19.5 percent, with dependency-chain tracking up 53.5 percent. The agent finally remembers what happened on the second Tuesday of March.
The root problem with agent memory
Current agent memory falls into two camps. Camp one: cram the full conversation history into the context window and pray the model can attend to it. When the window fills up, oldest messages get evicted. Camp two: embed everything into a vector store and retrieve the top-k chunks by cosine similarity at query time.
Both camps borrow from system engineering. Cache eviction, LRU policies, flat key-value stores. None of them model the three properties that make biological memory actually work: consolidation (moving important traces from short-term to long-term storage), forgetting (actively discarding low-value information to keep retrieval sharp), and reconsolidation (updating stored memories when new evidence conflicts with old beliefs).
The consequence shows up in long-horizon interactions. After 100-plus turns, agents lose temporal ordering, drop critical context, and start asking questions the user already answered. The paper's core claim is simple: memory is a process, not a storage problem. Model the process and long-horizon coherence follows.
Who and where
Alexander Bering, sole author, affiliated with Zensation AI. Submitted to arXiv on April 26, 2026, under identifier 2604.23878. Currently awaiting cs.AI endorsement. A discussion thread on HuggingFace Forums is active, with the author responding to technical questions about the architecture. The full text is available in arXiv HTML format.
Seven layers -- from working memory to cross-context
The architecture maps onto multiple-memory-systems theory from cognitive neuroscience (Atkinson-Shiffrin, Tulving's episodic/semantic distinction, Squire's procedural memory taxonomy). Seven layers, increasing in abstraction and stability.
| Layer | Name | Neuro analog | Role |
|---|---|---|---|
| L1 | Working Memory | Prefrontal working memory | Active context for the current turn, capacity-limited |
| L2 | Short-Term Memory | Hippocampal short-term store | Recent interaction buffer within a session |
| L3 | Episodic Memory | Hippocampal-cortical episodic | Spatiotemporal context of specific events |
| L4 | Semantic Memory | Temporal-lobe semantic store | Decontextualized facts, concepts, relations |
| L5 | Procedural Memory | Basal-ganglia/cerebellar procedural | Action sequences, tool-use patterns, habits |
| L6 | Core Memory | vmPFC self-referential store | User preferences, persona, long-term goals |
| L7 | Cross-Context Memory | Neocortical schema | Generalized knowledge shared across sessions |
The key mechanism is inter-layer migration. A short-term trace that recurs or carries emotional weight gets consolidated into episodic memory. An episodic memory that activates repeatedly gets abstracted into semantic memory. This mirrors the hippocampal-to-cortical consolidation pathway in biological brains.
L6, Core Memory, is modeled after the ventromedial prefrontal cortex's self-referential processing. It holds the user's fundamental preferences and identity-level information, managed not as a static profile but through the FSRS (Free Spaced Repetition Scheduler) algorithm. Stability updates dynamically based on activation frequency and prediction error.
L7, Cross-Context Memory, is the most novel layer. It extracts patterns that appear across different conversation sessions and promotes them to schemas. If a user consistently prefers concise responses in coding sessions and writing sessions alike, that preference becomes a cross-context schema. Most existing agent memory systems treat sessions as isolated silos. This layer bridges them.
Nine algorithms borrowed from neuroscience
The seven layers are the skeleton. The nine algorithms are the muscles. Each translates a specific neuroscience mechanism into software.
Two-Factor Synaptic Model. Derived from BCM theory of synaptic plasticity. Memory strength is the product of activation frequency and recency, not frequency alone. This drives inter-layer migration decisions.
vmPFC-coupled FSRS. Pairs the Free Spaced Repetition Scheduler with vmPFC self-referential processing to manage Core Memory stability. First application of FSRS to agent memory.
Simulation-Selection Sleep. Offline processing that mimics sleep-dependent memory consolidation. During agent downtime, episodic memories are replayed; important ones promote to semantic memory, unimportant ones decay. The numbers are striking: 37 percent stability improvement with 47.4 percent storage reduction. Less memory, better quality.
NeuromodulatorEngine. Simulates four neuromodulatory channels: dopamine (reward signaling), norepinephrine (arousal/attention), serotonin (mood/stability), and acetylcholine (learning rate). The combination of these four channels determines encoding strength and retrieval priority. An unexpected outcome (high dopamine signal) amplifies encoding of the associated episode.
ReconsolidationEngine. Gated by prediction error. When a retrieved memory conflicts with current context, it enters a labile state and can be updated. This models the well-established finding that recalling a memory makes it temporarily malleable. Existing agent memory systems treat stored memories as immutable, which causes accuracy drift over time.
TripleCopyMemory. Maintains three copies of each memory with divergent decay rates -- fast, medium, and slow. This yields S(t) = 0.912 stability at 30 days. A single copy with one decay curve forces a tradeoff between short-term responsiveness and long-term retention. Three copies with divergent decay sidestep this tradeoff.
PriorityMap. A four-dimensional priority map over time, emotion, relevance, and frequency. Includes an amygdala fast-path: emotionally significant memories get priority even when other dimensions score low. NDCG@10 = 0.997 means the top-10 retrieval ranking is near-perfect.
StabilityProtector. Software analog of NogoA (which inhibits synaptic rewiring) and HDAC3 (which regulates gene expression to prevent memory over-modification). In ZenBrain it brakes the ReconsolidationEngine, preventing overly aggressive updates to stable Core and Semantic memories.
MetacognitiveMonitor. Monitors system-wide memory state for conflicts, inconsistencies, and overload. Decides when intervention is needed. Models the human experience of knowing you know something but not being able to recall it precisely.
Benchmark results
| Benchmark | Metric | Flat store | RAG-based | ZenBrain | Improvement |
|---|---|---|---|---|---|
| LoCoMo | F1 (overall) | 0.42 | 0.51 | 0.62 | +21.6% vs RAG |
| LoCoMo | F1 (temporal) | 0.18 | 0.22 | 0.61 | +176% vs RAG |
| MemoryArena | Overall score | 0.38 | 0.47 | 0.56 | +19.5% vs RAG |
| MemoryArena | Dependency chains | 0.28 | 0.34 | 0.52 | +53.5% vs RAG |
| Sleep effect | Stability change | - | - | +37% | - |
| Sleep effect | Storage change | - | - | -47.4% | - |
| TripleCopy | S(t) at 30 days | - | - | 0.912 | - |
| PriorityMap | NDCG@10 | - | - | 0.997 | - |
The temporal query improvement stands out. Questions like "what budget item did we discuss three weeks ago on Tuesday" are nearly impossible for vector-similarity-only retrieval because cosine distance does not encode calendar time. ZenBrain's episodic memory preserves spatiotemporal context, which is why temporal F1 jumps from 0.22 to 0.61.
The dependency chain gain of 53.5 percent matters for production agents running long projects. Tracking multi-step causal chains -- "we decided A, which changed B, which forced a re-evaluation of C" -- requires the kind of structured episodic and semantic memory that flat stores cannot provide.
Why this is interesting -- industry implications
First, it reframes the problem. Agent memory research has been about storage and retrieval. ZenBrain redefines it as a lifecycle problem: encoding, consolidation, retrieval, reconsolidation, forgetting. If this frame is correct, the research agenda shifts from "better embeddings and retrieval" to "better memory lifecycle management."
Second, the Simulation-Selection Sleep result has direct cost implications. A 47.4 percent storage reduction while improving stability by 37 percent means cheaper vector DB bills and better performance simultaneously. For production deployments serving millions of users, that arithmetic adds up fast.
Third, cross-context continuity. If L7 works as described, an agent could reference "the coding style you preferred last week" during a writing session. Most current agents reset at session boundaries or carry forward only a compressed summary. True cross-session context continuity is a prerequisite for agents that function as genuine personal assistants rather than stateless tools.
Caveats and open questions
The biggest question is production scalability. Running seven layers and nine algorithms simultaneously introduces computational overhead. The paper reports benchmark scores but omits latency and throughput numbers. Simulation-Selection Sleep requires an asynchronous processing pipeline during agent downtime, and the engineering complexity of that pipeline is nontrivial.
The single-author status also warrants caution. Alexander Bering and Zensation AI do not have a widely documented prior research track record. The ideas are novel and the benchmark numbers are impressive, but independent reproduction has not yet been published. The paper is currently seeking cs.AI endorsement on arXiv, which itself is an unusual status for a paper making such strong claims. Until an independent team reproduces these results, a degree of skepticism is reasonable.
What to check tomorrow morning
The question ZenBrain raises is clear: should agent memory design keep borrowing from system engineering (caches, databases, paging), or should it adopt the memory lifecycle from neuroscience?
If you are building agent memory right now, three checks are worth doing immediately. One: does your system have a forgetting mechanism? Storing everything forever is actually a performance liability. Two: can your system handle temporal-condition queries? Vector similarity alone cannot do temporal reasoning. Three: does context carry across sessions? Most agents have a hard reset at session boundaries, and that is a ceiling on usefulness.
The full paper is available at arXiv 2604.23878, with an HTML version for easier reading. The author is actively discussing the architecture on the HuggingFace Forums thread.
관련 기사

OCR-Memory: Optical Context Retrieval for Long-Horizon Agent Memory
In plain terms: render the agent's long history into images (with visual anchors), then locate-and-transcribe the relevant region back to text — high-density memory with less hallu

GenericAgent: A Token-Efficient Self-Evolving LLM Agent via Contextual Information Density Maximization (V1.0)
In plain terms: a self-evolving LLM agent that maximizes decision-relevant info density in a finite context, cutting tokens 89.6% over 9-round repeated GitHub research tasks.
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.