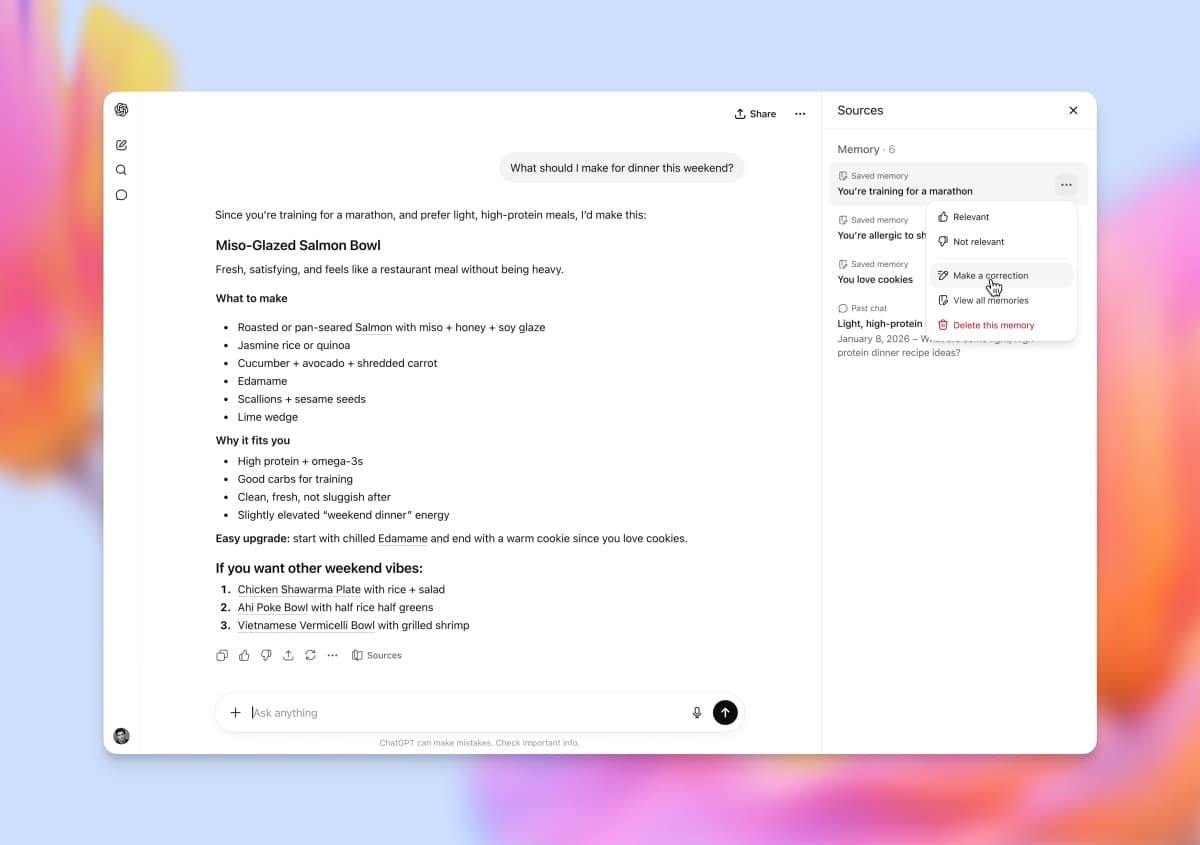
OpenAI, GPT-5.5 Instant을 ChatGPT 기본 모델로 — 환각 52.5% 감소, 'yapping' 30% 감소
5월 5일 OpenAI가 ChatGPT 기본 모델을 GPT-5.5 Instant으로 교체했어. 의료·법률·금융 같은 고위험 프롬프트의 환각이 GPT-5.3 Instant 대비 52.5% 줄었고, 응답 길이도 30.2% 짧아졌어. API 별칭은 chat-latest.
환각 52.5% 감소 — 'GPT가 적게 거짓말하기' 시작했어
5월 5일 OpenAI가 ChatGPT 기본 모델을 GPT-5.5 Instant으로 교체했어. 발표 자체는 짧았지만 숫자가 굵직해. 의료·법률·금융 같은 'high-risk' 프롬프트에서 환각률이 직전 모델(GPT-5.3 Instant) 대비 52.5% 감소. 사용자가 'difficult' 태그로 신고한 까다로운 대화의 부정확 클레임은 37.3% 감소. 그리고 응답이 평균 30.2% 짧아지고 줄 수도 29.2% 줄어 'yapping(쓸데없이 말 늘리기)'이 줄었어. API 별칭은 chat-latest. 이게 사소해 보이지만 실제로 ChatGPT 사용자 8억 명의 일상 경험을 한 단계 끌어올린 업그레이드야.
각 주체 — OpenAI, ChatGPT 사용자, 경쟁자, API 개발자
먼저 OpenAI. 2026년 5월 시점 ChatGPT 주간 활성 사용자(WAU)가 8억 명, 유료 플랜이 1.5억 명. 이 규모에서 기본 모델을 바꾸는 건 단순한 모델 업데이트가 아니라 '제품 핵심 자산 교체'야. GPT-5는 2025년 8월, GPT-5.3 Instant이 2026년 2월에 default가 됐고, 이번 5.5 Instant은 약 3개월 만의 교체. OpenAI 모델 교체 주기가 점점 빨라지고 있어 (1년 → 6개월 → 3개월).
ChatGPT 사용자 8억 명에게는 가장 실질적인 변화. (1) 의료·법률·금융 질문에서 환각이 절반으로 줄어. (2) 응답이 30% 짧아져 읽기 부담이 감소. (3) 'difficult' 라벨 대화에서 부정확 클레임이 37% 감소. 무료 사용자도 즉시 이 모델로 자동 전환. Pro/Plus 사용자는 'GPT-5 Thinking'과 'GPT-5.5 Instant' 사이를 직접 선택할 수 있어.
경쟁자 — Anthropic Claude, Google Gemini, Meta Llama, xAI Grok. 모두 환각 감소 경쟁에서 OpenAI에 뒤처지지 않으려 다음 모델 출시 일정을 앞당기는 중. 특히 Claude Opus 5(2025년 12월 출시)가 환각 부문에서 SOTA로 평가받았는데, 이번 GPT-5.5 Instant이 일부 벤치마크에서 Claude를 따라잡거나 추월했다는 평가.
API 개발자에게는 'chat-latest' 별칭이 핵심. 기존 'gpt-5.3-instant' 같은 명시 모델명 대신 'chat-latest'로 호출하면 OpenAI가 자동으로 최신 default 모델로 라우팅. 즉 개발자가 코드 변경 없이 latest 성능을 받을 수 있는 구조. 다만 모델 변경 시 출력 분포가 달라져 prompt engineering 재조정이 필요해.
핵심 내용 — 환각·yapping·instruction following 세 축의 개선
OpenAI가 발표한 내부 평가 데이터를 표로 정리하면 이렇게 돼.
| 평가 축 | GPT-5.5 Instant | GPT-5.3 Instant 대비 | 의미 |
|---|---|---|---|
| 고위험 프롬프트 환각률 | 측정값 미공개 | -52.5% | 의료·법률·금융 |
| 사용자 신고 'difficult' 부정확 | 측정값 미공개 | -37.3% | 까다로운 대화 |
| 응답 평균 길이 | 측정값 미공개 | -30.2% | 'yapping' 감소 |
| 응답 평균 줄 수 | 측정값 미공개 | -29.2% | 가독성 향상 |
| Instruction following 점수 | 측정값 미공개 | 개선 (수치 미공개) | 명령 추종 |
이 표에서 가장 흥미로운 건 'yapping 감소' 항목. 2024-2025년 ChatGPT 사용자 불만 1순위가 '간결하게 답해 달라고 해도 길게 답한다'는 거였어. GPT-5.3 Instant이 평균 387단어로 응답했다면 5.5 Instant은 약 270단어. 30% 단축이 사용자 만족도에 즉시 영향.
환각 감소 52.5%가 진짜 의미하는 건 'medical advice', 'legal interpretation', 'financial recommendation' 같은 카테고리에서 fabricated citations(존재하지 않는 논문·법조문 인용)이 절반으로 줄었다는 거야. ChatGPT 의료 질문 사용자의 60% 이상이 의사 외 일반인이라는 점을 감안하면 사회적 파급이 크지. OpenAI는 이번 모델에서 'high-stakes prompt detection' 분류기를 강화해 환각 가능성이 높을 때 '나는 의료 전문가가 아닙니다' 명시 + 추가 출처 검증을 자동 수행하도록 했어.
Instruction following 개선은 ChatGPT가 'follow instructions exactly'에 더 충실하게 됐다는 의미. 예를 들어 '한 단어로만 답해'라는 지시를 받으면 GPT-5.3 Instant은 50% 정도 따랐는데 5.5 Instant은 약 80%. 이게 prompt engineering 분야에서 '실용 가치 50% 상승'이라고 평가되는 부분.
훈련 방법론 측면에서 OpenAI는 RLHF 변형인 'Process Reward Modeling(PRM)'과 새 'Constitutional Self-Critique'을 결합했어. PRM은 답변의 추론 과정 각 단계에 점수를 매기는 방법이고, Self-Critique는 모델이 자기 답변을 다시 평가해 환각 가능성을 자기 표시하는 방식. 두 방법의 조합이 환각 52.5% 감소의 기술적 핵심.
각자의 이득 — OpenAI, 사용자, 광고주, 의료·법률 전문가
OpenAI에게는 두 가지 큰 이득. 첫째 'inference cost 절감'. 응답이 30% 짧아진다는 건 토큰 출력이 30% 줄어들어 GPU 추론 비용이 그만큼 줄어든다는 거야. WAU 8억 × 일평균 5쿼리 × 토큰 30% 감소 = 추론 비용 연간 약 8-12억 달러 절약 추정. 둘째 '사용자 retention'. 환각 감소·yapping 감소가 직접 만족도 개선 → churn 감소로 연결.
ChatGPT 사용자에게는 의료·법률·금융 질문에서 더 안전한 답변. 다만 '안전한 답변'이 항상 '유용한 답변'은 아니야. 일부 사용자는 GPT-5.5 Instant이 '너무 조심스러워졌다'고 불평. 답변이 짧아지고 의학적 disclaimer가 늘어나면서 '구체적 정보가 줄었다'는 피드백도 있어.
광고주에게는 ChatGPT가 '신뢰할 수 있는 정보 채널'로 한 단계 더 이동. OpenAI가 2026년 하반기 ChatGPT 광고 시범 도입을 검토 중인데, 환각률이 낮아질수록 광고 통합 가능성이 높아져. 정확한 정보 옆에 광고가 붙는 게 잘못된 정보 옆 광고보다 브랜드 안전성 측면에서 훨씬 유리.
의료·법률 전문가에게는 양면 효과. 부정적 측면은 'GPT가 더 정확해지면 사용자가 더 의존' → 전문가 자문 수요 감소 가능성. 긍정적 측면은 'GPT가 자체 한계 인식' → 어려운 케이스에서 '전문가에게 가세요' 권유가 늘어 진짜 어려운 사례가 전문가에게 더 잘 도달.
과거 유사 사례 — GPT-3.5 default 교체와 Claude Opus 5
성공 사례 첫째는 2023년 11월 GPT-3.5에서 GPT-4-turbo default 교체. 그때 환각 35% 감소·응답 속도 2배 향상. 그 후 ChatGPT Plus 구독자 수가 2개월 만에 2배 증가. Default 모델 교체가 비즈니스 지표에 직접적 영향이 있다는 첫 번째 검증.
성공 사례 둘째는 2024년 5월 GPT-4o default 교체. 멀티모달(이미지·오디오) 통합으로 ChatGPT 일일 활성 사용자가 1억 → 2억으로 더블. 'Default 교체 = 사용자 경험 점프 = 신규 사용자 유입' 등식이 성립한 두 번째 사례.
실패 사례는 2024년 8월 Anthropic의 Claude 3.5 Sonnet → Claude 3.5 Haiku default 단기 교체 시도. Anthropic이 비용 절감을 위해 Claude.ai default를 Sonnet에서 Haiku로 바꿨는데, 사용자 항의로 2주 만에 롤백. 'Default 교체 시 비용 절감 우선이면 사용자 경험이 무너진다'는 교훈.
가장 가까운 비교는 2025년 12월 Claude Opus 5 출시. Anthropic이 Opus 5를 default 모델로 ChatGPT를 잠깐 따라잡았다는 평가를 받았어. 다만 Anthropic의 default 교체는 무료 사용자가 아닌 Pro/Max 사용자 한정이어서 영향 규모가 OpenAI보다 작았어. 이번 GPT-5.5 Instant은 무료 사용자까지 포함이라 영향이 훨씬 커.
경쟁자 카운터 플레이 — Claude, Gemini, Llama, Grok
Anthropic Claude는 가장 직접적 경쟁자. Claude Opus 5가 환각 부문에서 SOTA였는데 GPT-5.5 Instant이 일부 따라잡거나 추월했어. Anthropic이 Claude Opus 6 출시를 6월에서 5월로 앞당겼다는 보도가 5월 8일 나왔어. 환각·instruction following 부문에서 다시 SOTA를 가져오려는 의도. 더불어 Anthropic은 'Constitutional AI' 자체 방법론으로 OpenAI Self-Critique과 다른 접근.
Google Gemini는 검색 통합 강점. Gemini 2.5 Pro가 web search를 default로 통합해 환각 가능성을 외부 정보로 줄이는 방식. OpenAI도 이번 5.5 Instant에서 search-augmented 응답 비중을 늘렸지만, Google의 인덱스 우위를 따라잡기는 어려워. 다만 ChatGPT WAU 8억 vs Gemini WAU 추정 4억으로 사용자 규모는 OpenAI 우위.
Meta Llama는 오픈소스 진영. Llama 4(2025년 12월), Llama 5(2026년 6월 예상)가 default 모델 경쟁에는 직접 참여하지 않지만, 엔터프라이즈 시장에서 'self-host = OpenAI vendor lock-in 회피'로 차별화. 환각 vs instruction following에서 Llama 4 405B는 GPT-5.3과 비슷한 수준이라 Llama 5가 5.5 Instant 수준에 도달할지가 6월 이후 관전 포인트.
xAI Grok은 다른 게임. Grok 4·5는 'censorship-free·spicy' 캐릭터로 차별화. 환각률은 GPT-5.5 Instant보다 30-50% 높지만 사용자가 그 점을 알고 사용. X 통합과 머스크 개인 브랜드 효과로 일정 사용자층 유지. 단 환각 부문 경쟁에는 직접 참여하지 않음.
중국 경쟁자는 Moonshot AI Kimi K2, DeepSeek R3, Qwen3, MiniMax M2 등. 환각률 부문에서 GPT-5.5 Instant 대비 약간 뒤지지만 가격이 1/5 수준이라 가성비 경쟁. 다만 미국 정부가 5월 5일 'Microsoft·Google·xAI 사전 배포 검토(CAISI 협약)' 정책을 발표한 상황이라, 중국 모델의 미국 시장 진입은 제한적.
그래서 뭐가 달라지는데 — 일반 사용자·개발자·기업 IT
일반 ChatGPT 사용자에게는 두 가지 실질적 변화. 첫째 의료·법률·금융 질문에서 답변 신뢰도가 즉시 상승. 'ChatGPT 의사' 활용이 늘어날 것으로 예상되지만, 동시에 'AI에 의존하다 진짜 의사 방문 시점을 놓친다'는 부작용도 함께 와. 둘째 답변이 짧아져 읽기 시간이 줄어. 평균 사용자 대화 1건당 30초 정도 시간 절약 추정.
API 개발자에게는 'chat-latest' alias의 활용 방식이 핵심. 기존 코드를 수정 없이 latest로 자동 업그레이드 받으려면 'chat-latest', 안정성 우선이면 'gpt-5.3-instant' 명시. 단 'chat-latest'는 출력 분포가 변경 가능성이 있어 프로덕션 환경에서는 (1) prompt engineering 재조정 (2) eval suite 재실행 (3) A/B 테스트 권장.
기업 IT 팀에게는 'ChatGPT Enterprise default 교체'가 핵심 결정. ChatGPT Enterprise는 organization admin이 default 모델을 명시 지정 가능. 5.5 Instant이 default가 됐다고 자동 적용되지는 않고, admin이 수동 활성화 필요. 환각 52.5% 감소가 컴플라이언스 측면에서 매력적이지만, 출력 분포 변경으로 기존 워크플로 재검증 필요.
스타트업 창업자에게는 'OpenAI 모델 교체 주기가 3개월로 단축됐다'는 점이 가장 큰 시그널. 자체 fine-tuning 모델로 차별화하려면 OpenAI의 base 모델 업그레이드 속도를 따라잡아야 하는데, 3개월 주기는 fine-tuning 회사들에게는 거의 불가능한 cadence. 'OpenAI base + custom prompt' 패턴이 'OpenAI fork + heavy fine-tuning' 패턴보다 ROI가 점점 더 높아져.
마지막으로 academia·정부 연구 관점에서는 'GPT-5.5 Instant 환각 감소가 진짜인가' 검증이 필요. OpenAI 내부 평가 데이터만 공개됐고 외부 벤치마크 결과(MMLU, GPQA, MedQA, HALoGEN)는 아직 없어. 외부 평가가 6월까지 나오면서 실제 환각 감소 폭이 확인되면 '52.5% claim'의 신뢰성이 확정. 그 전까지는 OpenAI 발표를 그대로 믿기보다는 외부 검증 결과를 기다리는 게 합리적.
참고 자료
출처
관련 기사

AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.