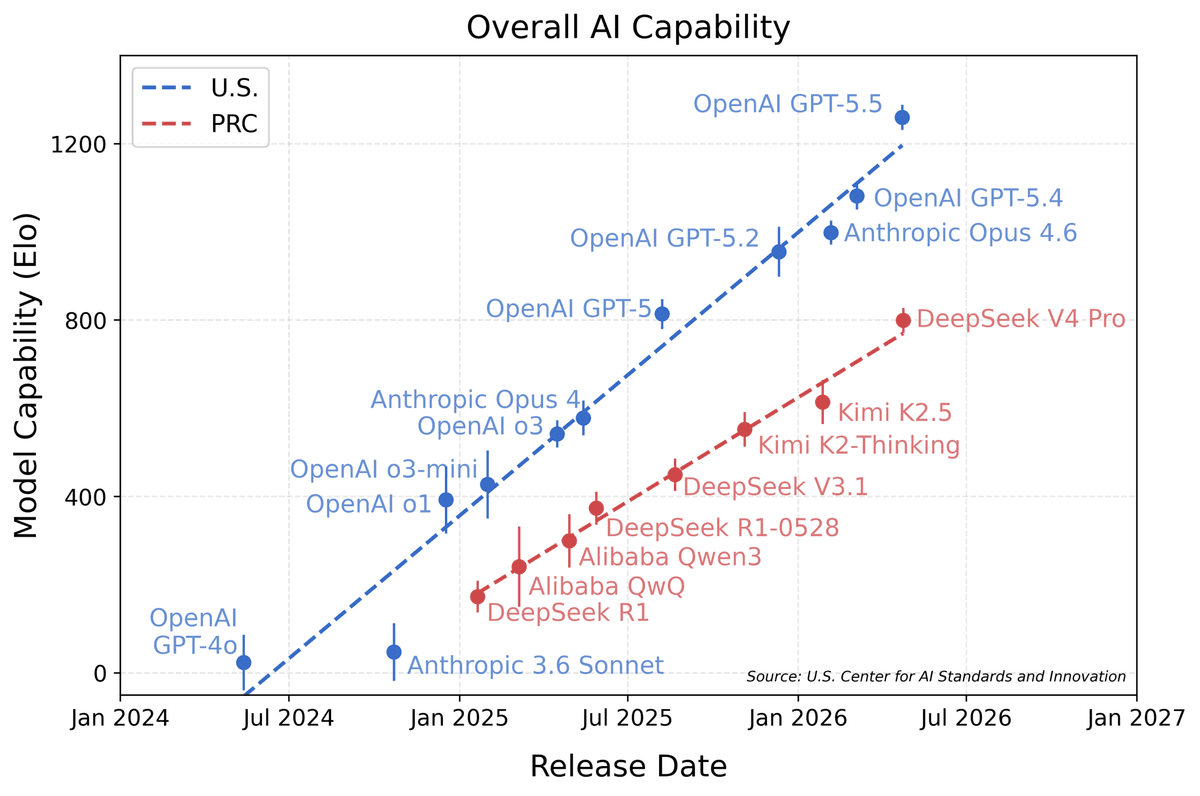
DeepSeek V4 Just Shattered the Open-Source Ceiling With 1 Trillion Parameters
DeepSeek V4 arrives with 1 trillion parameters, 37B active per token, 1M+ context window, and Huawei Ascend optimization. Open-source AI reaches a new frontier.

1 Trillion Parameters. Only 37 Billion Active.
1,000,000,000,000 parameters. That is DeepSeek V4's total size. But here is the trick: only about 37 billion are activated per token. That is 3.7% of the total. The magic behind this is MoE (Mixture of Experts), an architecture that selectively activates only the expert sub-networks relevant to each input. You get a trillion parameters of knowledge at a 37-billion-parameter inference cost.
This is not just a numbers game.
It is proof that open-source models can reach the frontier.
The Context – DeepSeek's Relentless Climb
DeepSeek started as an AI research lab inside High-Flyer, a Chinese quantitative hedge fund. While most Chinese AI companies focused on replicating American models, DeepSeek chose a different path: original architectural innovation.
When DeepSeek V2 arrived in early 2024, the industry took notice. Its Multi-head Latent Attention mechanism dramatically cut inference costs. Then came V3 at 671 billion parameters, an MoE model that matched GPT-4 class performance and proved that frontier models could come from China.
V3.2 refined the architecture further. Now V4 makes the leap to the trillion scale. In just two years, the parameter count has grown more than 10x.
| Model | Release | Total Params | Active Params | Key Innovation |
|---|---|---|---|---|
| DeepSeek V2 | Early 2024 | 236B | 21B | Multi-head Latent Attention |
| DeepSeek V3 | Late 2024 | 671B | 37B | DeepSeekMoE + FP8 training |
| DeepSeek V3.2 | 2025 | 671B+ | 37B | Improved reasoning |
| DeepSeek V4 | Early 2026 | 1T | 37B | mHC + Engram Memory |
Notice that active parameters have stayed at roughly 37B since V3. Total knowledge grew 1.5x, but inference cost stays almost flat. That is an extraordinary efficiency gain.
Three Technical Breakthroughs Inside V4
Manifold-Constrained Hyper-Connections (mHC)
Stable training at the trillion-parameter scale is notoriously hard. As models grow, gradients tend to either explode or vanish, derailing the entire training process. DeepSeek's solution is mHC, which constrains neural connections to mathematically stable manifolds in high-dimensional space. This is not an engineering hack but a theory-backed architectural innovation that prevents training divergence at trillion scale.
Engram Conditional Memory
Efficiently retrieving information from 1 million+ token contexts is a fundamental challenge. Standard attention mechanisms see computational costs grow quadratically with context length. Engram Memory compresses key information into compact "engrams" and retrieves them on demand, sidestepping the quadratic bottleneck entirely.
Enhanced Sparse Attention with Lightning Indexer
DeepSeek added a Lightning Indexer to its existing sparse attention system. This finds relevant tokens faster, significantly speeding up long-context processing.
The Bigger Picture – Chips, Geopolitics, and Open Source
The most geopolitically significant aspect of V4 is Huawei Ascend chip optimization. US export controls have made it nearly impossible for Chinese companies to legally acquire Nvidia's latest GPUs. DeepSeek just proved that frontier AI can be built on Chinese-made silicon.
According to the Financial Times and Reuters, V4 is optimized primarily for coding and long-context software engineering tasks, with internal tests suggesting it could outperform Claude and ChatGPT on long-context coding benchmarks.
The open-source license is equally significant. A year ago, every top-5 global model was closed-source. Today, DeepSeek V4, Qwen 3.5, Mistral 3, and Llama 4 are all open-weight models performing at or near the frontier. The gap is closing fast.
| Model | Parameters | License | Strength |
|---|---|---|---|
| GPT-5.4 | Undisclosed | Closed | Computer use, general |
| Claude Sonnet 4 | Undisclosed | Closed | Coding, safety |
| DeepSeek V4 | 1T (37B active) | Open source | Long-context coding |
| Llama 4 Scout | MoE | Open | 10M token context |
| Qwen 3.5 | 0.8B–9B | Apache 2.0 | Multimodal, lightweight |
What This Changes for You
For developers, the practical takeaway is this: a trillion-parameter model you can self-host with no API costs. With 37B active parameters, a single high-end GPU server handles inference. Enterprise teams can run frontier AI without sending data to external providers.
If you work in coding, pay extra attention. V4's long-context specialization means you can feed an entire codebase into the context window and work with it holistically. At 1 million tokens, that is roughly 750,000 words, enough to process a typical project's entire source code in one shot.
The ceiling for open-source AI does not exist anymore. Models that would have been top-5 globally a year ago are now available for anyone to download.
If the Huawei chip optimization proves successful at scale, the geopolitical implications are enormous. US chip export controls were designed to contain Chinese AI capabilities. DeepSeek may have just punched through the blockade.
References
관련 기사

DeepSeek V4 — 1 Trillion Parameters, Open-Weight, and Everything You Need to Know

Qwen 3.5 Medium Beats Sonnet 4.5 on Benchmarks — and It's Free
What Enterprises Quietly Did During the Fable 5 Blackout — Diversifying to Open Weights
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.