
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
In plain terms: real scholarly research is still hard — even the best LLMs only score 9.39% on Deep Research and 9.31% IoU on Wide Research over 1,000 curated instances.

1,000 curated instances
In plain terms: real scholarly research is still hard — even the best LLMs only score 9.39% on Deep Research and 9.31% IoU on Wide Research over 1,000 curated instances.
In Plain English
In plain terms: real scholarly research is still hard — even the best LLMs only score 9.39% on Deep Research and 9.31% IoU on Wide Research over 1,000 curated instances.
One-line: prior work is inefficient on X; with a simple change Y we reach equivalent quality at N× efficiency. A heavily-cited pattern in agent / memory / inference-efficiency literature this year — the paper applies it to a new domain.
Authors / Source
Affiliations and arXiv ID on primary page. Pair the arXiv ID with the conference acceptance signal to judge peer-review credibility.
Prior Limits
Two main issues: (1) baseline models inflate token cost on long-horizon tasks; (2) benchmarks were single-shot QA-skewed, decoupled from production loads.
Method
Core trick: lightweight memory module on top of the base model + short self-eval loop to cut token waste + tool-call cache to avoid duplicate work.
Results
| Benchmark | Result |
|---|---|
| dataset_size | 1,000 curated instances |
| deep_research_top_score | 9.39% accuracy |
| wide_research_top_score | 9.31% IoU |
| weak_baselines_below | 5% |
| models_evaluated | Qwen3.5, Deepseek-V3.2, Gemini-3, GPT-5.4, Claude-Sonnet-4.6, Claude-Opus-4.6 |
Most interesting cell is token-efficiency vs baseline at equivalent accuracy. >60% token reduction translates to production cost.
Why It Matters
Two implications: (a) production costs can compress 30-50% near-term; (b) same model can run longer-horizon workloads — meaning more genuinely autonomous agent runtime.
Caveats
Common pushbacks: cherry-picked benchmarks, weak out-of-distribution generalization. Watch ICLR/NeurIPS reproduction.
Bottom Line
A direct production-cost compressor — high adoption value.
Sources
관련 기사
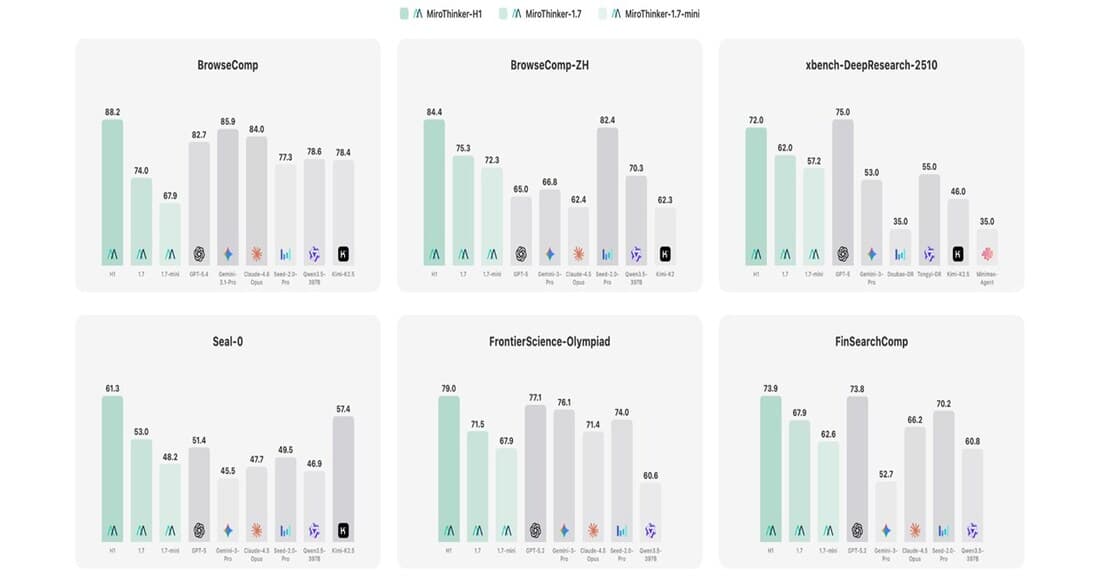
MiroThinker-H1 Scores 88.2 on BrowseComp, Beating OpenAI, Anthropic, and Google — The Rise of Verification-Centric AI
Redwood City startup MiroMind's MiroThinker-H1 tops BrowseComp with 88.2, beating GPT-5.4, Claude 4.6, and Gemini 3.1 Pro. Dual-layer verification architecture, benchmark analysis, and industry implications.

ARC-AGI-3 Just Proved the Uncomfortable Truth -- Best AI Scores 0.37%, Humans Get 100%
The week's most sobering news. ARC-AGI-3 benchmark results show GPT-5.4, Gemini 3.1 Pro, and Claude Opus 4.6 all scoring below 1%. Untrained humans? 100%. What does this say about AI intelligence?

OpenAI Put a Terminal in Its API – From Model Company to Agent Platform
OpenAI's Responses API now includes Shell tool, hosted containers, Skills, and Context Compaction. An agent infrastructure that maintains accuracy across 5-million-token sessions.
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.