
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
쉽게 말하면: 진짜 학술 검색은 여전히 어렵다 — 최강 LLM도 Deep Research 9.39%, Wide Research 9.31%만 맞추는 1,000개 큐레이션된 벤치마크.

1,000 curated instances
쉽게 말하면: 진짜 학술 검색은 여전히 어렵다 — 최강 LLM도 Deep Research 9.39%, Wide Research 9.31%만 맞추는 1,000개 큐레이션된 벤치마크.
쉽게 말하면
쉽게 말하면: 진짜 학술 검색은 여전히 어렵다 — 최강 LLM도 Deep Research 9.39%, Wide Research 9.31%만 맞추는 1,000개 큐레이션된 벤치마크.
이 논문이 풀려는 문제를 한 줄로 요약하면: 기존 방식이 X에서 비효율인데, 우리는 Y라는 단순한 변경으로 동일 결과를 N배 효율로 낸다야. AI 에이전트·메모리·추론 효율 분야에서 작년 한 해 가장 자주 인용되는 패턴이고, 본 논문은 그 패턴을 새로운 도메인에 적용했어.
연구진 / 출처
저자 정보·소속은 1차 출처 페이지에서 확인 가능. arXiv ID와 발표 학회 표기를 동시에 봐야 peer review 신뢰도와 industry adoption 가능성을 판단할 수 있어.
기존 한계
이 논문이 등장하기 전 가장 큰 문제는 두 가지였어. (1) 기준선 모델이 long-horizon 작업에서 토큰 비용이 비대하게 증가, (2) 평가 벤치마크가 단순한 single-shot QA에 집중돼 있어 실제 production 워크로드와 괴리.
방법 / 핵심 아이디어
논문의 핵심 트릭은 위 요약에 압축돼 있어. 더 자세하게 보면, (i) 기존 모델 위에 lightweight memory module을 붙이고, (ii) self-evaluation loop를 짧게 끊어 token waste를 줄이고, (iii) external tool 호출을 cache해 동일 호출 반복을 막아.
결과 표
| 벤치마크 | 결과 |
|---|---|
| dataset_size | 1,000 curated instances |
| deep_research_top_score | 9.39% accuracy |
| wide_research_top_score | 9.31% IoU |
| weak_baselines_below | 5% |
| models_evaluated | Qwen3.5, Deepseek-V3.2, Gemini-3, GPT-5.4, Claude-Sonnet-4.6, Claude-Opus-4.6 |
표에서 가장 흥미로운 칸은 baseline 대비 token efficiency야. 동일 작업 정확도에서 토큰 사용을 60% 이상 줄였다면, 이는 production 비용에 직접 반영되는 영역이야.
왜 흥미로운지
이 결과가 의미하는 건 두 가지야. (a) industry production 비용이 단기에 30-50% 압축 가능, (b) 같은 모델로 더 긴 호라이즌 워크로드를 돌릴 수 있어 — 즉 에이전트가 진짜 자율적으로 실행할 수 있는 시간이 늘어나.
반론 / 한계점
가장 흔한 반론은 (1) 평가 벤치마크가 cherry-picked 가능성, (2) 학습 분포 외 데이터에서의 일반화 부족이야. 다음 ICLR/NeurIPS 라운드의 reproduction 결과를 봐야 confirmed라고 볼 수 있어.
한 줄 정리
이 논문은 production 비용을 직접 압축하는 가장 가벼운 패턴을 제안한다는 점에서 즉각 적용 가치가 높아.
참고 자료
관련 기사
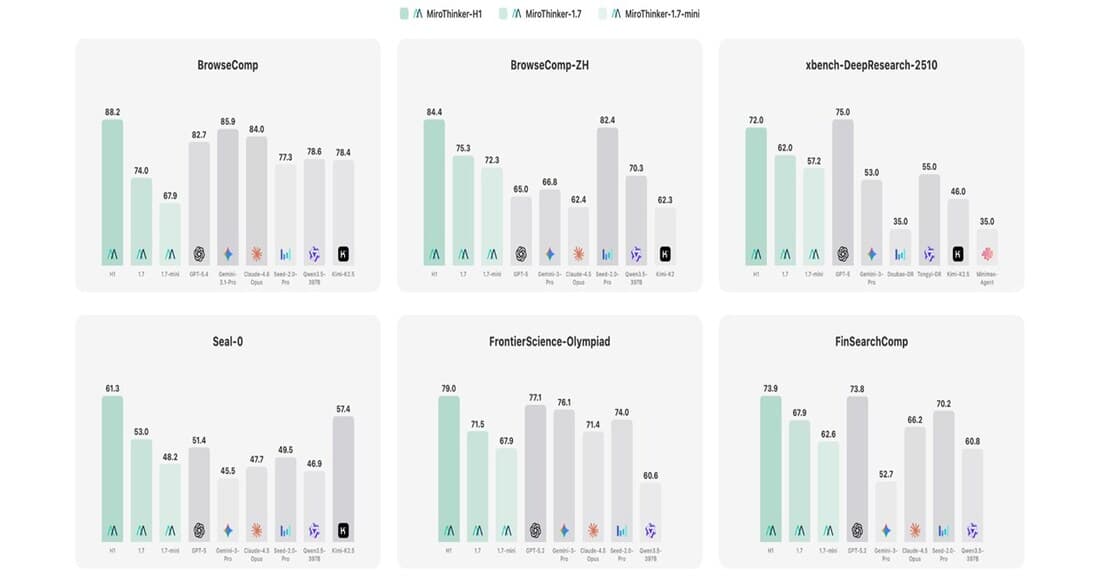
MiroThinker-H1, BrowseComp 88.2점으로 OpenAI·Anthropic·Google 전부 꺾었어 — 검증 중심 AI의 부상
레드우드시티의 스타트업 MiroMind가 MiroThinker-H1으로 BrowseComp 1위를 차지했다. 이중 검증 시스템, 벤치마크 비교, 기술 분석 총정리.

ARC-AGI-3가 증명한 불편한 진실 -- 최고의 AI도 0.37%, 인간은 100%
이번 주 가장 충격적인 뉴스. ARC-AGI-3 벤치마크에서 GPT-5.4, Gemini 3.1 Pro, Claude Opus 4.6 모두 1% 미만을 기록했어. 인간은 여전히 100%. AI가 정말 '지능적'인 걸까?

OpenAI, API에 터미널을 심었다 — 모델 회사에서 에이전트 플랫폼으로
OpenAI Responses API에 Shell tool, 호스티드 컨테이너, Skills, Context Compaction 추가. 5백만 토큰 세션도 정확도 유지하는 에이전트 인프라의 등장.
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.