
Graphs + LLMs + Agents — A Mapping-Book Survey for the Graph-Agent Era
Cross-institution survey on integrating structured graphs (knowledge, scene, causal, dependency) with LLMs and agents for reasoning, retrieval, generation, and recommendation. Three-axis taxonomy plus a comparative analysis of four integration strategies.

A Mapping Book
arXiv 2604.15951 (April 19) is a cross-institution survey on the intersection of structured graphs (knowledge, scene, causal, dependency, interaction) with LLMs and agents — laying out reasoning, retrieval, generation, and recommendation use cases. It's a reference, not a single result: a starting map for anyone entering the area.
In Plain Terms
LLMs are great at text but inefficient at multi-relational facts ("CEO of company X, which acquired Y, whose product launches next week"). Graphs encode such relations natively. The integration friction is that LLMs don't take graphs as input directly. Four strategies have emerged — prompting, augmentation, training, agent-based — each with different cost/accuracy/training-burden trade-offs. The survey lays them out side by side.
Authors and Source
Cross-institution survey rather than a single lab. arXiv 2604.15951, CC-BY, posted April 19, 2026. Survey-format paper with method classification, comparative analysis, and a future-directions section.
Limits the Survey Addresses
A hundred-plus graph-LLM integration papers shipped 2023-2025 with no canonical map. Practitioners typing "knowledge graph + LLM" hit prompting, augmentation, joint-training papers indiscriminately and didn't know where to start.
Method — 3-Axis Taxonomy + 4 Integration Patterns
Three axes. Purpose: reasoning / retrieval / generation / recommendation. Graph modality: knowledge graph (entity relations), scene graph (image-object relations), interaction graph (user behavior), causal graph, dependency graph (code/document). Integration strategy: prompting (serialize graph to text and put in prompt), augmentation (RAG-like external boost), training (joint graph-encoder + LLM), agent-based (LLM calls graph DB as a tool).
Trade-Off Table
| Pattern | Accuracy | Cost | Training burden | Best fit |
|---|---|---|---|---|
| Prompting | Mid | Low | None | Small graphs, one-off |
| Augmentation (RAG-like) | Mid-high | Mid | Low | Large KG, RAG-fluent teams |
| Training (joint encoding) | High | Very high | Very high | Domain-specific, long-lived |
| Agent-based (graph as tool) | Mid-high | Mid-high | Mid | Complex multi-step reasoning |
Representative papers anchor each pattern. Microsoft GraphRAG is a canonical augmentation example; LangChain Graph Cypher agents are the agent-based reference. Same-week ReaLM-Retrieve sits in augmentation × reasoning.
Why It Matters
Three reasons. One: industry adoption acceleration — enterprises hit the "LLMs don't know our internal facts" wall, and graph integration is the leading answer; a clear taxonomy speeds choice. Two: the survey landed the same week as Microsoft GraphRAG v0.5 — graph-RAG is becoming production-ready and the survey is its reference paper. Three: in agent systems, structured memory is back in fashion, and graphs are the leading candidate for that structure.
Limits and Skeptics
Two. The taxonomy is academic-clean — production systems usually mix patterns (GraphRAG itself uses prompting + augmentation), so the cleanness can mislead. Real-world ops case studies are not the focus and have to be sourced separately.
One-Liner
The mapping book for graph × LLM × agent. Tells newcomers where to start and existing builders where their pattern sits.
References
- Paper: https://arxiv.org/abs/2604.15951
- Microsoft GraphRAG: https://github.com/microsoft/graphrag
- ReaLM-Retrieve: https://arxiv.org/abs/2604.26649
- Neo4j: https://neo4j.com/
관련 기사

GPT-5.4 Thinking Ships — 33% Fewer Tokens, 33% Fewer Errors, and the Reasoning AI Tipping Point
OpenAI released GPT-5.4 Thinking with 33% fewer reasoning tokens, 33% fewer factual errors, and GDPVal 83.0%. Full model family, pricing, benchmarks, and what it means for developers.
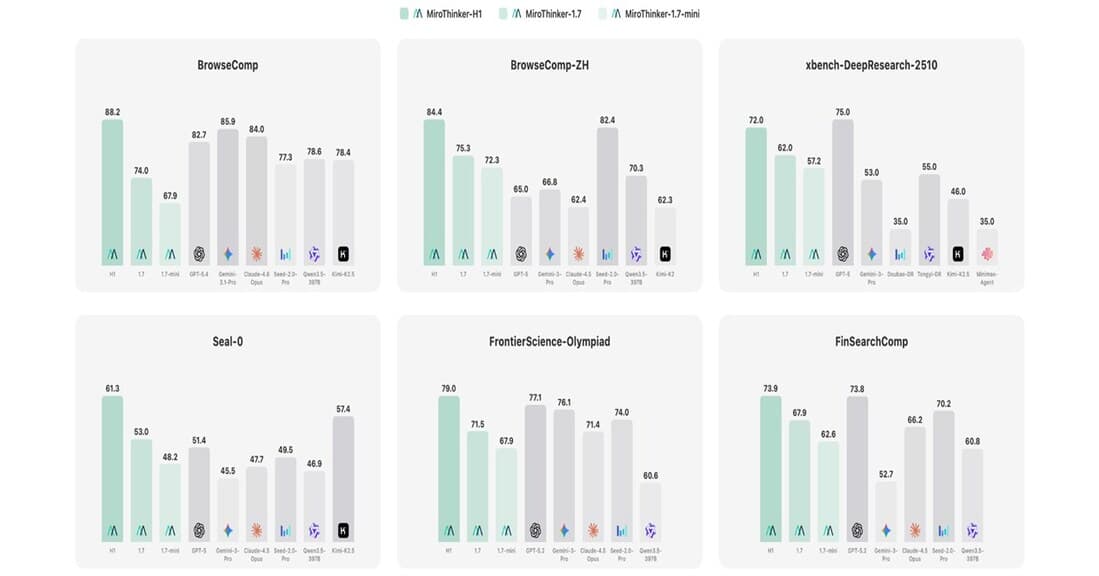
MiroThinker-H1 Scores 88.2 on BrowseComp, Beating OpenAI, Anthropic, and Google — The Rise of Verification-Centric AI
Redwood City startup MiroMind's MiroThinker-H1 tops BrowseComp with 88.2, beating GPT-5.4, Claude 4.6, and Gemini 3.1 Pro. Dual-layer verification architecture, benchmark analysis, and industry implications.

ARC-AGI-3 Just Proved the Uncomfortable Truth -- Best AI Scores 0.37%, Humans Get 100%
The week's most sobering news. ARC-AGI-3 benchmark results show GPT-5.4, Gemini 3.1 Pro, and Claude Opus 4.6 all scoring below 1%. Untrained humans? 100%. What does this say about AI intelligence?
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.