
Graphs + LLMs + Agents — 그래프-에이전트 시대의 매핑북 서베이
지식 그래프·장면 그래프·인과 그래프 같은 구조화된 그래프를 LLM·에이전트와 어떻게 묶어야 reasoning/retrieval/생성/추천이 잘 되는지 정리한 cross-institution 서베이. 3축 분류 + 4가지 통합 패턴 trade-off 비교.

그래프 × LLM × 에이전트의 매핑북
arXiv 2604.15951 서베이가 4월 19일 풀렸어. 그래프(지식, 장면, 인과, 의존 등)와 LLM, 그리고 에이전트가 만나는 자리에서 reasoning/retrieval/생성/추천 4가지 목적이 어떻게 풀리는지 cross-institution으로 정리한 reference야. 단발 연구 결과가 아니라 매핑북 — 즉 이 영역에 처음 들어가는 사람이 어디서 시작해야 할지를 알려 주는 자료야.
쉽게 말하면
LLM은 텍스트를 잘 다루지만 "이 사람이 저 회사 CEO인데 그 회사가 인수한 회사의 제품을 출시"같은 다중 관계는 토큰 시퀀스로 표현하기 비효율적이야. 그래프 자료구조(노드 + 엣지)는 이 다중 관계를 자연스럽게 담아. 문제는 LLM이 그래프를 직접 입력으로 못 받는다는 점인데, 이걸 해결하는 방법이 prompting/augmentation/training/agent-based 4가지로 나뉘고, 각 방법의 trade-off가 다 달라. 이 서베이가 그 trade-off를 정리해.
연구진과 출처
cross-institution 서베이라 단일 랩이 아니야. arXiv 2604.15951, CC-BY, 2026-04-19 공개. 정확한 저자단은 arXiv 등재 시점에 확인 가능. 형식상 서베이 논문이라 (방법 분류 + 비교 + 미래 방향 제시) 구조.
기존 한계 — 그래프-LLM 통합이 ad-hoc하던 시대
2023-2025 동안 그래프-LLM 통합 논문이 100편 이상 쏟아졌는데, 어느 방법이 어느 시나리오에 가장 좋은지가 정리되지 않았어. 같은 "knowledge graph + LLM" 키워드로 검색하면 prompting 방식 논문, augmentation 방식 논문, joint training 방식 논문이 다 나오는데 각각 상황이 달라. 실무자 입장에서는 어디서 시작해야 할지 막막한 상태였어.
방법 — 3축 분류 + 4가지 통합 패턴
서베이의 분류 체계는 3축이야. 목적 축: reasoning / retrieval / generation / recommendation. 그래프 모달리티 축: knowledge graph(엔티티 관계), scene graph(이미지 객체 관계), interaction graph(사용자 행동), causal graph(인과 관계), dependency graph(코드/문서 의존). 통합 전략 축: prompting(그래프를 텍스트로 변환해 prompt에 넣기), augmentation(그래프 검색을 RAG처럼 외부 보강), training(그래프 인코더를 LLM에 결합 학습), agent-based(LLM이 그래프 DB를 도구로 호출).
결과 표 — 4가지 통합 패턴 trade-off
| 패턴 | 정확도 | 비용 | 학습 부담 | 적합 시나리오 |
|---|---|---|---|---|
| Prompting (그래프 → 텍스트) | 중간 | 저 | 없음 | 작은 그래프, 단발 사용 |
| Augmentation (RAG-like) | 중상 | 중 | 낮음 | 큰 KG, 표준 RAG 익숙한 팀 |
| Training (joint encoding) | 상 | 매우 고 | 매우 고 | 도메인 특화, 장기 운영 |
| Agent-based (graph as tool) | 중상 | 중상 | 중 | 복잡 다단계 reasoning |
각 패턴별로 대표 논문이 reference로 정리돼 있어. 예를 들어 prompting은 GraphRAG (Microsoft)이 reference, agent-based는 LangChain의 Graph Cypher Agent 패턴이 reference. 같은 주에 풀린 ReaLM-Retrieve는 augmentation × reasoning 카테고리에 속해.
왜 흥미로운지
세 가지 의미가 있어. 첫째, 산업 채택 가속의 시발점. 그래프-LLM 통합은 enterprise 시장에서 "LLM이 회사 내부 지식을 정확히 다루지 못한다"는 한계의 답으로 주목받고 있는데, 어느 패턴을 쓸지 가이드가 없으면 채택이 느려져. 이 서베이가 그 가이드를 깔아 줘. 둘째, 4월 후반 Microsoft GraphRAG의 v0.5 release와 같은 주에 풀린 게 우연이 아니야 — 그래프-RAG 패턴이 production-ready로 자리잡는 사이클의 시작 신호. 셋째, 에이전트 시대에 "구조화된 메모리"가 다시 중요해지고 있는데, 그 구조 후보 1순위가 그래프야. 이 서베이는 그 흐름의 reference paper.
반론 / 한계점
서베이의 한계 두 가지. 첫째, 분류 축이 학술 위주라 실무 채택 케이스 study가 부족해. "이 패턴을 production에 깔았더니 이런 문제가 있었다"는 운영 사례는 각자 찾아봐야 함. 둘째, 분류 체계가 깨끗하긴 한데 실제 시스템은 여러 패턴을 hybrid로 쓰는 경우가 많아 — 예를 들어 GraphRAG도 prompting + augmentation 둘 다 씀. 분류가 너무 깔끔하면 실무 복잡성을 오해할 수 있음.
한 줄 정리
그래프 × LLM × 에이전트 영역의 매핑북. 처음 들어가는 사람에게 어디서 시작할지 알려 주고, 이미 들어간 사람에게는 본인 패턴이 어디 위치하는지 보게 해 주는 reference.
참고 자료
- 논문: https://arxiv.org/abs/2604.15951
- Microsoft GraphRAG: https://github.com/microsoft/graphrag
- ReaLM-Retrieve (관련 RAG): https://arxiv.org/abs/2604.26649
- Neo4j: https://neo4j.com/
관련 기사

GPT-5.4 Thinking 출시 — 33% 적은 토큰으로 33% 적은 오류, 추론 AI의 실용화 전환점
OpenAI가 GPT-5.4 Thinking을 공개했다. 추론 토큰 33% 절약, 팩트 오류 33% 감소, GDPVal 83.0%. 모델 패밀리, 벤치마크, 의미 총정리.
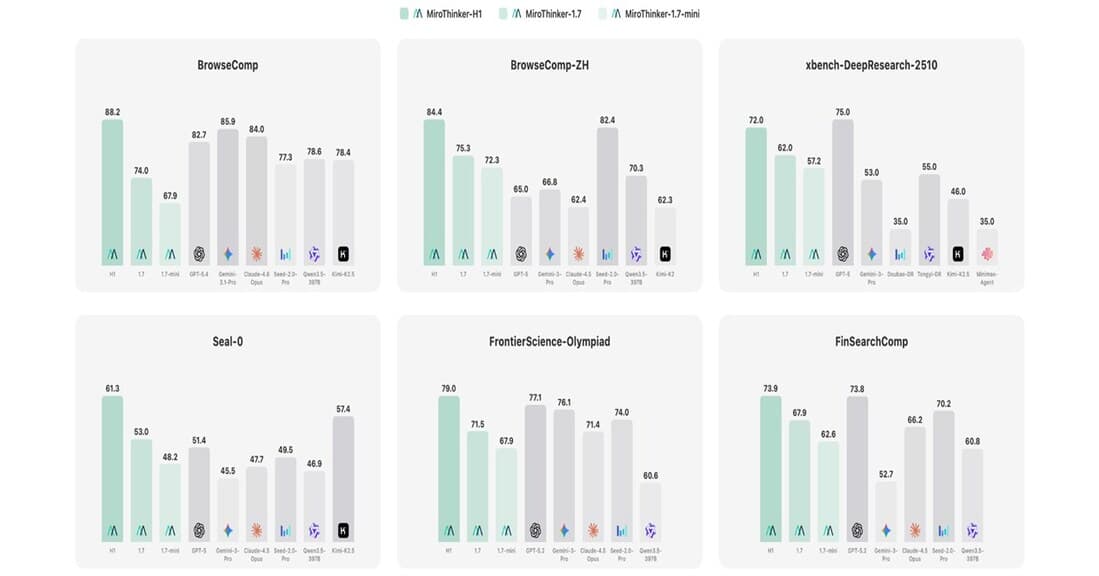
MiroThinker-H1, BrowseComp 88.2점으로 OpenAI·Anthropic·Google 전부 꺾었어 — 검증 중심 AI의 부상
레드우드시티의 스타트업 MiroMind가 MiroThinker-H1으로 BrowseComp 1위를 차지했다. 이중 검증 시스템, 벤치마크 비교, 기술 분석 총정리.

ARC-AGI-3가 증명한 불편한 진실 -- 최고의 AI도 0.37%, 인간은 100%
이번 주 가장 충격적인 뉴스. ARC-AGI-3 벤치마크에서 GPT-5.4, Gemini 3.1 Pro, Claude Opus 4.6 모두 1% 미만을 기록했어. 인간은 여전히 100%. AI가 정말 '지능적'인 걸까?
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.