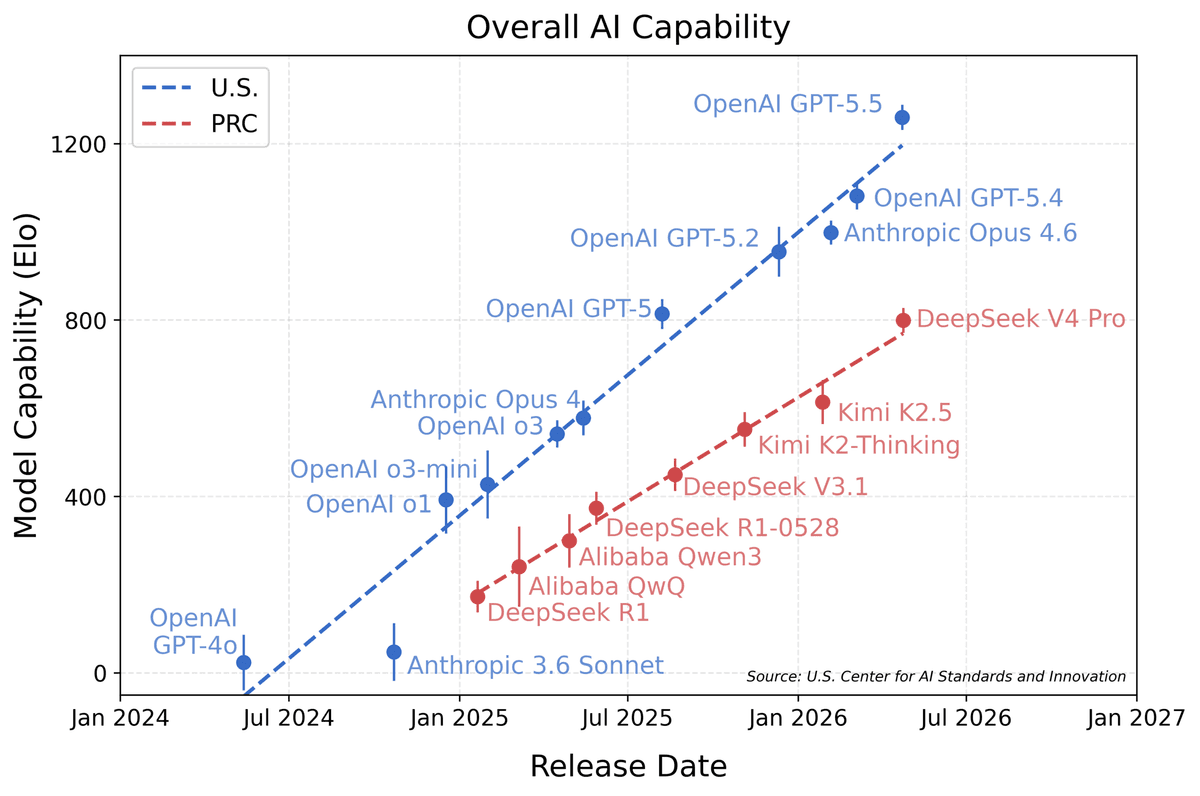
GPT-5.4가 OSWorld-V 75%를 받았어 — 자율 워크플로 시대로
OpenAI가 GPT-5.4를 공개. 100만 토큰 컨텍스트와 함께, 여러 소프트웨어를 넘나드는 멀티스텝 자율 실행이 핵심. OSWorld-V 벤치마크 75% 기록.
75%
OSWorld-V에서 75%를 받았어. 이게 GPT-5.4의 발표 카드 중 가장 큰 숫자야. OSWorld-V는 실제 데스크톱 환경에서 멀티스텝 작업(파일 열기→편집→저장, 여러 앱 넘나들기 등)을 채점하는 벤치마크인데, 직전 세대(GPT-5 표준)는 약 51%, 현 SOTA였던 Claude Sonnet 4.5가 65%였어.
이번 발표의 본질은 "컨텍스트가 길어졌다"가 아니라 "에이전트가 실제 일을 한다"야.
각 주체 — OpenAI와 자율 실행 전략
OpenAI의 GPT 라인은 5.0(2025년 1분기)에서 통합 모델 라인을 정리한 뒤, 5.x 세대를 분기마다 점진적으로 굴려왔어. 5.1·5.2는 멀티모달 정렬, 5.3은 도구 호출 정확도, 그리고 5.4가 "자율 워크플로"에 초점을 맞췄어.
Sam Altman이 작년 말부터 반복한 메시지가 있어 — "다음 단계는 답이 아니라 실행이다." 그 메시지의 첫 측정값이 OSWorld-V 75%야.
Jakub Pachocki는 Mira Murati CTO 사임 이후 사실상 모델 아키텍처 의사결정의 중심이 됐어. 5.4 학습 레시피는 "툴 사용 트레이스"를 메인 학습 신호로 격상한 게 핵심이라고 Greg Brockman 사장이 인터뷰에서 언급했어.
[IMG#1]
핵심 스펙
| 스펙 | GPT-5.4 | GPT-5 (직전) | Gemini 3.1 Ultra | Claude 4.5 Opus |
|---|---|---|---|---|
| 컨텍스트 | 1,000,000 | 256,000 | 2,000,000 | 500,000 |
| OSWorld-V | 75% | 51% | 미공개 | 65% |
| SWE-bench Verified | 71% | 64% | 68% | 70% |
| 멀티스텝 자율 | ✅ | 부분 | ✅ | ✅ |
| 입력 가격 ($/1M) | $5.00 | $5.00 | $1.25 | $15.00 |
| 출력 가격 ($/1M) | $15.00 | $15.00 | $5.00 | $75.00 |
표가 보여주는 건 두 축이야. OSWorld-V·SWE-bench 같은 "에이전트 벤치"에서 OpenAI가 일시적 1번을 회복했고, 가격은 직전과 동일이야 — 단, Gemini 3.1 Ultra의 $1.25 입력 단가에 비해 4배 비싸. OpenAI는 능력으로, Google은 가격으로 차별화하는 구도야.
멀티스텝 자율이 진짜 의미하는 것
데스크톱에서 파일 5개를 열고, 그 중 3개를 비교한 뒤, 결과를 노션에 저장하고, 슬랙에 알리는 과제를 하나의 프롬프트로 던지면 끝나야 해. GPT-5.4의 데모에서 그 흐름이 평균 4-7개의 도구 호출과 2-4개의 앱 전환으로 끝나는 걸 보였어.
핵심은 "오류 회복"이야. 도구 호출이 실패하거나 앱이 응답하지 않을 때, 모델이 백오프하고 다시 시도하는 패턴이 학습돼 있어. 이전 세대는 첫 실패에서 멈추거나 반복 루프에 빠지는 게 주된 실패 모드였어.
각자의 이득
OpenAI에게 — 에이전트 벤치 1번 자리를 회복했어. 그러나 가격에서 Google에 밀리고 있어서, "능력으로 프리미엄을 정당화한다"는 포지셔닝이 더 분명해졌어. ChatGPT Plus·Team·Enterprise 가격이 같이 올라갈 가능성도 있어.
기업 자동화 벤더에게 — UiPath·Workato·Zapier 같은 노코드 자동화 회사들이 GPT-5.4를 백엔드 LLM으로 채택하면 "에이전트 RPA" 카테고리가 1년 안에 굳어져.
Mira Murati — OpenAI 떠난 뒤 Thinking Machines Lab을 차렸는데, 5.4의 멀티스텝 카드는 그녀의 Thinking Machines가 같은 카테고리에서 일하기 더 어렵게 만든 면이 있어.
[IMG#2]
과거 유사 사례 — 에이전트 벤치 진화
OSWorld는 Tianbao Xie 외 (2024) 연구진이 만든 벤치마크야. 처음 등장 때 GPT-4가 12%, Claude 3가 14%로 처참한 점수였어. 1년 만에 65%, 그리고 또 8개월 만에 75%까지 올라온 거야.
비슷한 곡선이 SWE-bench에서도 나왔어. 2024년 초 Devin이 13.86%로 처음 등장, 1년 후 70%대까지 올라온 패턴이지. "벤치 도입 → 1.5-2년에 60-75%"는 표준 곡선이 됐어.
경쟁자 카운터 플레이
Google — Gemini 3.1 Ultra의 200만 토큰 + 코드 실행으로 "긴 컨텍스트 + 자율 코딩"을 미는 중. OSWorld-V 점수를 아직 공개 안 한 게 약점이야.
Anthropic — Claude Sonnet 4.6에서 코딩·MCP 도구 사용 정확도를 강조. SWE-bench에서 GPT-5.4와 1%p 차이까지 좁혔지만 OSWorld-V에서는 10%p 차이가 남.
Meta — Llama 5 발표에서 "오픈 가중치 자율 에이전트"를 띄운다는 회자. 가중치를 자체 호스팅 가능한 점이 차별화 카드야.
스테이크
- Wins: OpenAI — 에이전트 벤치 1번, ChatGPT Enterprise 갱신 협상력 회복.
- Wins: 자동화 SaaS — 같은 모델 위에 RPA 사용 사례를 쌓을 수 있음.
- Loses: 단순 LLM 래퍼 스타트업 — 자율 실행이 LLM 기본 기능이 되면 차별화 어려움.
- Watching: 규제 — 에이전트가 자율적으로 파일·이메일을 만지면 GDPR·SOC2 책임 분기가 모호.
- Watching: 내부 직원 자동화 — 회사 내부 도구의 RBAC가 LLM 자율 실행을 어떻게 통제할지.
반대 의견
Andrej Karpathy: "OSWorld-V는 큐레이션된 태스크라 실제 사용 분포와 차이가 있다 — 75%가 곧 프로덕션 75%는 아니다."
또 다른 비판은 Yann LeCun (Meta): "벤치 점수가 오르는 동안 환각·툴 오용 빈도가 함께 오르는지 모니터해야 한다." 자율 실행 환경에서 환각은 "글이 틀린 것"이 아니라 "파일을 잘못 지우는 것"이 되거든.
그래서 뭐가 달라지는데
개발자에게는 — GPT-5.4 Tools API가 멀티스텝 자율을 1급 기능으로 노출. 에이전트 빌드는 단일 LLM call이 아니라 "session 기반 멀티스텝"이 디폴트가 됐어.
창업자에게는 — RPA·자동화 SaaS의 진입 장벽이 다시 낮아졌어. 단, 차별화는 "도메인 데이터·정책·통합"이지 모델 자체가 아니야.
투자자에게는 — Microsoft(MSFT) Q2 결과에서 ChatGPT Enterprise 갱신율 + Azure AI Workload 매출이 핵심. OpenAI 점유율이 다시 빠르게 오르면 Google·Anthropic의 시장 점유에 압박.
일반 사용자에게는 — ChatGPT의 "Tasks" 기능이 더 깊이 자동화돼. 매일 반복하는 워크플로(보고서 정리·메일 답변)에 GPT-5.4 에이전트를 시도해볼 만해.
3줄 요약
- GPT-5.4가 OSWorld-V 75% — 에이전트 벤치 새 SOTA, 멀티스텝 자율 실행이 핵심.
- 가격은 동결, Gemini의 $1.25에 비해 4배 비쌈 — 능력 vs 가격 차별화 구도.
- 자동화 SaaS·RPA의 카테고리가 굳어지고, 내부 RBAC·규제 정합성이 다음 과제.
참고 자료
- OpenAI — GPT-5.4 발표
- OSWorld 벤치마크 — 공식 페이지
- TechCrunch — GPT-5.4 핸즈온
- Bloomberg — OpenAI 매출 업데이트
- Andrej Karpathy — 벤치 해석 노트
출처
관련 기사

AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.