CAISI: DeepSeek V4 Pro Lags U.S. Frontier by ~8 Months, Still Most Capable PRC Model
NIST's CAISI released its evaluation of DeepSeek V4 Pro on May 3: GPT-5-class performance, ~8 months behind the U.S. frontier, but the most capable PRC model to date. DeepSeek beat GPT-5.4 mini on cost-efficiency in 5 of 7 benchmarks.
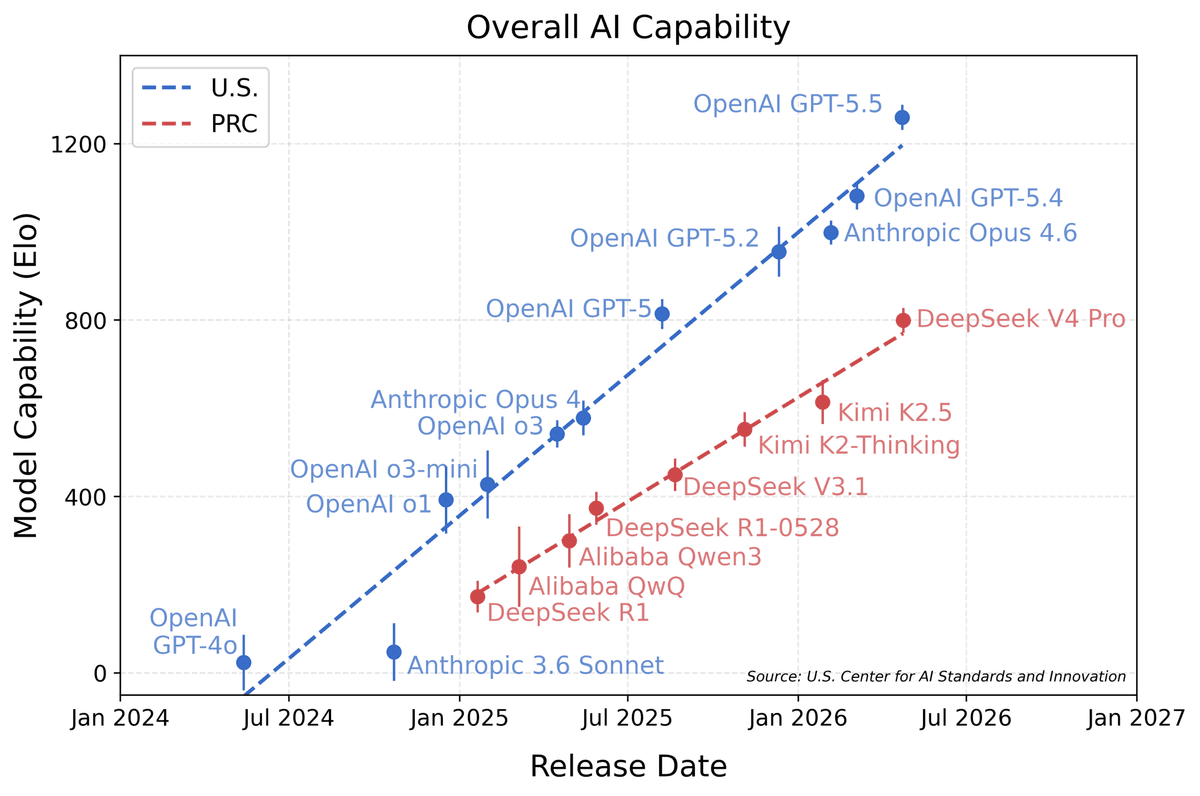
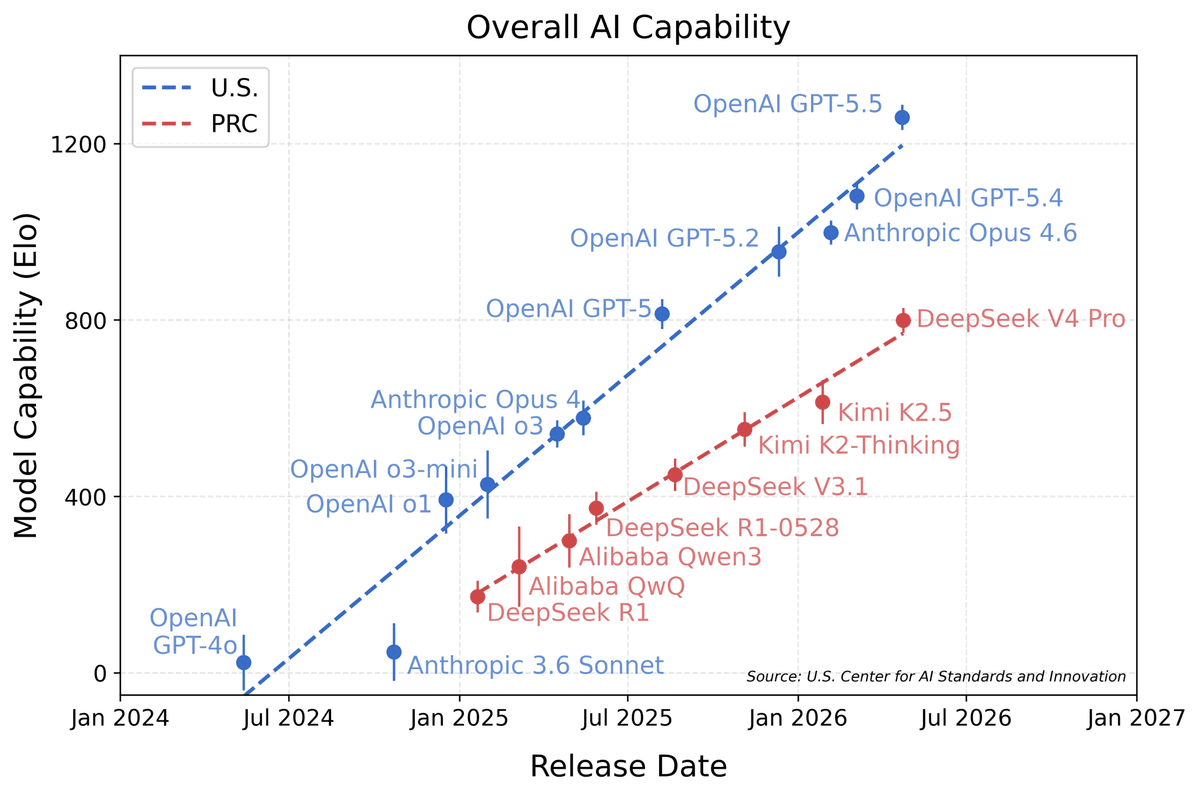
Eight Months — How Far the U.S. Says China's Best Model Is Behind
Here's the deal: on May 3, NIST's CAISI released its evaluation of DeepSeek V4 Pro. Bottom line: GPT-5-class performance, roughly 8 months behind the U.S. frontier, still the most capable PRC model to date. CAISI ran 9 benchmarks across 5 domains (cybersecurity, software engineering, natural sciences, abstract reasoning, mathematics), including ARC-AGI-2 semi-private and CAISI's internal PortBench benchmark — none of which are part of the public training-data corpus. The cost-efficiency story is the kicker: DeepSeek V4 Pro beat GPT-5.4 mini on 5 of 7 cost-efficiency benchmarks. The U.S. government just published "China is 8 months behind" while simultaneously confirming "China wins on cost-efficiency."
The Players — CAISI, DeepSeek, U.S. Frontier 5
CAISI was set up under NIST in 2024 and has run 40+ model evaluations. DeepSeek V4 Pro is one of the deeper assessments — including 2 confidential evaluations (ARC-AGI-2 semi-private set, internally developed PortBench).
DeepSeek launched in 2023 in Hangzhou, China, as a subsidiary of hedge fund High-Flyer. V1 through V3 led to V4 Pro. V4 Pro's two big technical advances: MoE architecture with ~70B active parameters for efficient inference, and RL-based reasoning fine-tuning that puts math/coding scores at the GPT-5 level. CEO Liang Wenfeng has been explicit since late 2024 about open-weights as the global market entry strategy.
The U.S. frontier comparators include OpenAI GPT-5/5.4/5.4 mini, Anthropic Claude Opus 5/Sonnet 5, Google Gemini 2.5/3, and xAI Grok 4. GPT-5 launched September 2025; GPT-5.4 mini is the cost-efficient variant from March 2026. The "8-month gap" isn't simply launch-date arithmetic; it's a translation of capability deltas back into time.
The Numbers — 9 Benchmarks, 5 Domains, 8-Month Gap
| Domain | Sample Benchmark | DeepSeek V4 Pro | U.S. Frontier (GPT-5.4) | Gap |
|---|---|---|---|---|
| Cyber | CTF, vuln discovery | GPT-5 class | GPT-5.4 ahead | ~8 mo |
| Software engineering | SWE-bench Verified | 70-75% | 80-85% | ~6-9 mo |
| Natural sciences | GPQA Diamond | 75-80% | 85-90% | ~9-12 mo |
| Abstract reasoning | ARC-AGI-2 semi-private | 50-55% | 65-70% | ~12 mo |
| Mathematics | AIME, MATH | GPT-5 class | GPT-5.4 mini class | ~6-8 mo |
| Confidential | PortBench | undisclosed | undisclosed | undisclosed |
The biggest gap is on ARC-AGI-2: ~12 months on abstract reasoning and generalization. Critically, the semi-private set is held outside the public training corpus, so DeepSeek can't have trained on it.
Cost-efficiency is the live story. DeepSeek V4 Pro beat GPT-5.4 mini on 5 of 7 cost-efficiency benchmarks. Input pricing is roughly $0.07/1M tokens vs. GPT-5.4 mini's $0.15/1M, and output pricing tracks similarly. The U.S. is "8 months ahead on capability, behind on price-performance" — which the U.S. government just officially confirmed.
PortBench is the CAISI-internal benchmark. Exact details aren't disclosed, but it's described as "real-world cybersecurity + infrastructure penetration." DeepSeek V4 Pro's PortBench score being undisclosed signals government concern about Chinese model cyber capability.
Who Wins — U.S., China, Global Application Industry
U.S. government wins twice. The narrative — "China is 8 months behind" — combines with the same-week CAISI MOU expansion to package "U.S. frontier lead + government visibility" as a single policy story. It also justifies maintaining (and tightening) export controls on H200/B200 to China — "China is following at 8 months" supports the case that controls are buying time.
DeepSeek and the Chinese government get mixed signals. Negative: the official U.S. narrative says they're behind. Positive: cost-efficiency wins and U.S. government recognition of "best PRC model" elevate DeepSeek as a global player; open-weights positioning gives DeepSeek real footholds in non-U.S. markets where data sovereignty and price are dominant.
Global application industry — especially Southeast Asia, India, Latin America, Africa, the Middle East — gets a "GPT-5.4 mini-class capability at half the price" model. Where U.S. frontier models are too expensive to deploy at scale, DeepSeek V4 Pro becomes a serious option. Open-weights also enable self-hosting.
The open-source LLM ecosystem benefits substantially. If DeepSeek V4 Pro weights drop (or are imminent), academia and indie developers get a usable GPT-5-class model for fine-tuning, distillation, and specialization. Llama 3 in 2024 had this effect; V4 Pro could match or exceed it.
Past Parallels — Wins and Losses
DeepSeek V3 ramp (2024-12 → 2025-03): V3 cracked the global LLM usage top-5 in three months and became the most popular fine-tuning base for application startups. V4 Pro could trace a similar curve.
Llama 3 (2024-04): Meta's open-weights release exploded the global LLM application ecosystem — hundreds of fine-tuning, distillation, and specialization startups. With Llama 4 expected to slip to Q4 2026, DeepSeek V4 Pro fills the gap.
Mistral Large ramp limits (2024-2025): Mistral Large positioned as "EU sovereign frontier model" but hit a 5% global share ceiling — capability gap to GPT-4 plus no real price advantage. DeepSeek faces similar structural barriers in U.S. markets due to U.S. policy.
Chinese Qwen series global ramp (2024-2025): Alibaba Qwen ramped open-weights but stalled at 1-2% U.S./EU market share due to "Chinese model = data security risk" narratives. DeepSeek hits the same wall.
Counter-Plays — U.S. Frontier, Other Chinese Labs
U.S. frontier labs counter two ways. Capability-gap maintenance: GPT-6, Claude Opus 6, Gemini 3 ramps push the gap from 8 months to 12+. Cost-efficiency follow-on: gpt-5.4 mini, Claude Haiku 4.5, Gemini 2.5 Flash narrow DeepSeek's price lead.
Other Chinese labs (Alibaba Qwen, Tencent Hunyuan, Baidu ERNIE, MiniMax, Zhipu) use V4 Pro's evaluation as a ramp accelerator. Alibaba could pull Qwen 4 launch into Q3 2026; MiniMax differentiates further on video.
European models (Mistral, Aleph Alpha) struggle harder for differentiation. "EU sovereign + data sovereignty" remains, but cost and capability versus DeepSeek erode. Mistral Large 3 (Q4 2026 expected) will face price-cut pressure.
Open-source community (Llama, Stability, EleutherAI) actually benefits — DeepSeek attracts more contributors and fine-tuning attention. With Llama 4 delayed, DeepSeek fills the gap.
What Changes — Devs, Founders, Investors, End Users
Devs: a real "GPT-5-class at low cost" alternative now exists. Cost-sensitive workloads (content generation, classification, summarization) move to DeepSeek V4 Pro API at roughly half the GPT-5.4 mini price. Self-hosting brings unit costs near zero.
Founders: model selection actually diversifies. SaaS startups increasingly run dual-vendor (DeepSeek + U.S. frontier), improving COGS by 5-10 points over 12 months. U.S./EU regulated industry procurement still favors U.S. frontier.
Investors: Chinese AI infrastructure (custom GPUs, LLMs, services) gets a re-rating, and U.S. frontier pricing leverage faces new pressure — OpenAI/Anthropic ARR multiples could compress from 8-10× toward 6-7× over the next 12 months.
End users: lower LLM app pricing or better free tiers. ChatGPT, Claude, and Gemini face pricing pressure as DeepSeek-based applications proliferate. Consumer LLM unit costs could fall 30-40% over 6-12 months.
Stakes
- Wins: Liang Wenfeng (DeepSeek CEO) — official "best PRC model" + cost-efficiency lead acknowledged; global application industry — cost-efficient alternative; open-source LLM ecosystem — strong fine-tuning base.
- Loses: U.S. cost-efficient models (GPT-5.4 mini, Claude Haiku 4.5) — pricing leverage erosion; European models (Mistral, Aleph) — differentiation erosion; other Chinese labs (Alibaba, Tencent, Baidu) — DeepSeek dominates the China narrative.
- Watching: U.S. government (BIS, Commerce) — export-control adjustments; emerging markets (India, SEA, Middle East) — DeepSeek adoption pace; academia/open-source — V4 Pro weights release timing and license.
The Skeptics — "8-Month Gap is Imprecise"
Andrej Karpathy and similar academic/indie researchers argue the 8-month gap aggregates uneven domain gaps — 6-9 months in cyber/math, 12-18 months on ARC-AGI-2 — and a single number obscures that, potentially leading to policy mistakes.
Jim Fan (NVIDIA) and similar industry voices flag GPT-5 distillation as a likely contributor — DeepSeek V4 Pro absorbing GPT-5 outputs as training data could explain a fast capability catch-up while masking a 12-18 month native R&D gap.
Two skeptic lines: (1) single gap-number flattens domain variance, (2) distillation makes native R&D capability hard to measure. Both undermine "CAISI evaluation = precise capability measurement."
TL;DR
- CAISI's May 3 evaluation: DeepSeek V4 Pro at GPT-5 class, ~8 months behind U.S. frontier.
- 9 benchmarks across 5 domains. Most capable PRC model. Beats GPT-5.4 mini on 5/7 cost-efficiency benchmarks.
- Real cost-efficient alternative for global application industry; pressure on U.S. frontier pricing leverage.
References
출처
관련 기사
GPT-5.4 hits OSWorld-V 75% — autonomy goes mainstream

CAISI Signs Pre-Deployment AI Safety Deals with Google DeepMind, Microsoft, and xAI
DeepSeek Just Made Its 75% V4-Pro Price Cut Permanent — The AI Price War Moved From Promo to Structure
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.