CAISI "DeepSeek V4 Pro, 美 프런티어 대비 8개월 뒤져 — 中 최고 모델"
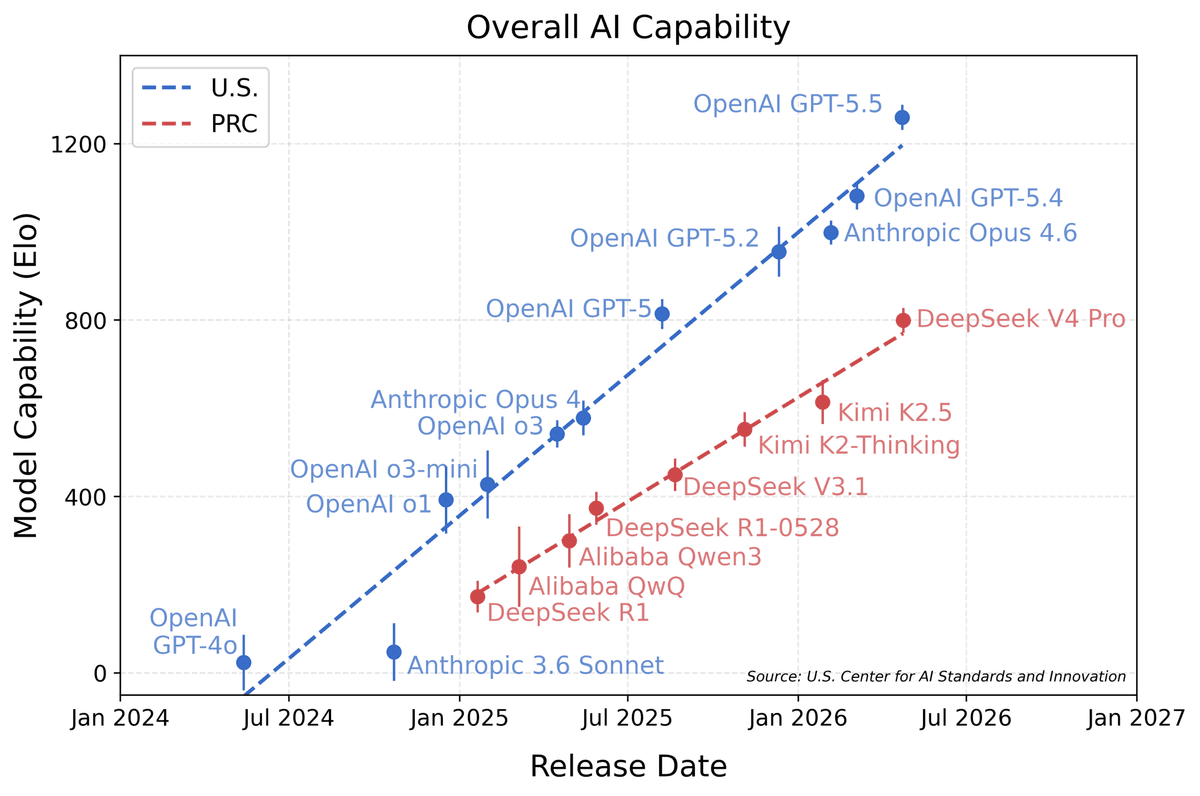
美 NIST 산하 CAISI가 5월 3일 평가 보고서에서 DeepSeek V4 Pro가 GPT-5 수준이며 미국 프런티어 대비 약 8개월 뒤처진다고 평가했어. 5개 영역에서 中 최고 성능을 보였고, 7개 비용 효율성 벤치마크 중 5개에서 GPT-5.4 mini를 이겼어.
8개월 — 美 정부가 中 최강 모델에 매긴 거리
5월 3일, 美 NIST 산하 CAISI(Center for AI Standards and Innovation)가 DeepSeek V4 Pro 평가 보고서를 발간했어. 결론 한 줄: GPT-5 수준 성능 + 미국 프런티어 대비 약 8개월 뒤처진다 + 그래도 지금까지 中 최고 모델이다. 평가는 5개 영역(사이버·소프트웨어 엔지니어링·자연과학·추상추론·수학)에서 9개 벤치마크로 진행됐고, ARC-AGI-2 semi-private + CAISI 자체 PortBench 비공개 평가 2개를 포함한 깊이 있는 분석이야. 더 흥미로운 건 비용 효율성 — 7개 벤치마크 중 5개에서 GPT-5.4 mini 대비 더 저렴하면서도 비슷하거나 나은 성능을 보였어. 이게 진짜 굵직한 부분이야 — 美 정부가 'China가 8개월 뒤진다'는 narrative를 공식 발표하면서도 'cost-efficient에서는 미국을 이긴다'는 사실을 인정한 첫 사례야.
각 주체 — CAISI, DeepSeek, 미국 프런티어 5사
먼저 CAISI. 2024년 NIST 산하에 설치된 평가 기관으로, 지금까지 40개 이상 모델을 평가했어. DeepSeek V4 Pro 평가는 'open-weight 中 모델의 진짜 능력 가시성'을 가져가려는 정부 의도가 명확해. 평가 시 안전장치를 부분적으로 또는 완전히 제거한 모델을 받아서 최악 시나리오를 시뮬레이션하는 게 특징이야.
DeepSeek는 2023년 中 항저우에서 출발한 AI 회사야. 헷지펀드 High-Flyer 자회사로 출범했고, V1~V3 시리즈를 거쳐 V4 Pro에 도달했어. V4 Pro의 핵심은 두 가지 기술 도약: 첫째 MoE(Mixture-of-Experts) 아키텍처로 활성 파라미터 약 70B로 효율적 추론, 둘째 강화학습 기반 추론 fine-tuning으로 GPT-5 급 수학·코딩 성능. CEO Liang Wenfeng가 2024년 말부터 'open-weight으로 글로벌 시장 진입'을 명시적 전략으로 잡았고, V4 Pro가 그 전략의 결실이야.
비교 대상이 된 미국 프런티어 모델은 OpenAI GPT-5·GPT-5.4·GPT-5.4 mini, Anthropic Claude Opus 5·Sonnet 5, Google Gemini 2.5·3, xAI Grok 4 등이야. CAISI 평가에서 GPT-5는 2025년 9월 출시 모델이고, GPT-5.4 mini는 2026년 3월 출시 비용 효율 모델이야. '8개월 뒤짐'은 GPT-5 출시 시점(2025-09) → DeepSeek V4 Pro 출시 시점(2026-04)의 단순 시간 차이가 아니라, '지금 GPT-5.4 수준에 도달하려면 8개월이 더 필요하다'는 능력 격차의 시간 환산이야.
中 정부에는 양면 의미야. 한편으로는 '中 최고 모델이 미국 1위 모델 대비 8개월'이라는 narrative가 부정적이지만, 다른 한편으로는 '中 모델이 美 정부 평가에서 GPT-5 급'이라는 인정이야. DeepSeek는 中 정부에 'open-weight으로 글로벌 시장 진출 가능'이라는 모델을 제공해.
핵심 내용 — 9 벤치마크·5 영역·8개월 격차
CAISI 평가의 9개 벤치마크 + 5개 영역을 표로 정리하면 이렇게 돼.
| 영역 | 벤치마크 (예시) | DeepSeek V4 Pro | 미국 프런티어 (GPT-5.4) | 격차 |
|---|---|---|---|---|
| 사이버 | CTF·Vulnerability discovery | GPT-5 급 | GPT-5.4 우위 | ~8개월 |
| 소프트웨어 엔지니어링 | SWE-bench Verified | 70-75% | 80-85% | ~6-9개월 |
| 자연과학 | GPQA Diamond | 75-80% | 85-90% | ~9-12개월 |
| 추상추론 | ARC-AGI-2 semi-private | 50-55% | 65-70% | ~12개월 |
| 수학 | AIME·MATH | GPT-5 급 | GPT-5.4 mini 동급 | ~6-8개월 |
| 비공개 (CAISI) | PortBench | 비공개 | 비공개 | 비공개 |
ARC-AGI-2가 가장 큰 격차 영역이야. 추상추론·일반화 능력에서 미국 프런티어가 12개월 우위를 가졌어. ARC-AGI-2 semi-private 셋이 외부에 공개되지 않은 평가 셋이라, DeepSeek가 학습 데이터로 흡수해서 점수를 부풀렸을 가능성이 차단된 평가야.
비용 효율성 결과가 진짜 흥미로워. 7개 벤치마크 중 5개에서 DeepSeek V4 Pro가 GPT-5.4 mini 대비 더 저렴하면서도 비슷하거나 나은 성능을 보였어. 입력 토큰 단가가 GPT-5.4 mini ($0.15/1M) 대비 DeepSeek V4 Pro ($0.07/1M)로 절반 수준이고, 출력 토큰 단가도 비슷한 비율이야. 즉 미국 프런티어가 '능력으로 8개월 앞서지만 비용 효율에서는 中에 진다'는 게 정부 공식 평가의 결론이야.
PortBench는 CAISI가 자체 개발한 비공개 평가야. 어떤 영역인지 정확히 공개되지 않았지만, 'real-world 사이버 보안 + 인프라 침투'에 가까운 평가로 알려져 있어. DeepSeek V4 Pro의 PortBench 점수가 비공개로 처리됐다는 게 'china 모델의 사이버 능력에 대한 정부 우려'를 시그널로 보낸 거지.
각자의 이득 — 미국, 中, 글로벌 응용 산업
미국 정부에는 두 가지 이득. 첫째 '中이 8개월 뒤진다'는 narrative 확보. 미국 5대 프런티어 랩이 정부 평가 체계에 들어가는 흐름(같은 주 발표된 CAISI MOU)과 결합해서 '미국 프런티어 우위 + 정부 가시성'이라는 정책 패키지가 만들어져. 둘째 수출 통제 정당화. NVIDIA H200·B200 등 첨단 GPU의 中 수출 통제를 유지·강화할 정당성이 강해져. 'china가 8개월 격차로 따라오는 중 = 통제 유지가 격차 확대로 이어진다'는 논리야.
DeepSeek·中 정부에는 양면 이득. 부정적 면은 narrative ('미국이 8개월 앞선다'). 긍정적 면은 두 갈래야. 첫째 '中 최고 모델로 글로벌 인정'. 미국 정부가 공식 평가를 한다는 건 DeepSeek가 글로벌 시장에서 무시할 수 없는 플레이어로 인정받았다는 의미야. 둘째 '비용 효율 우위'. 7/9 비용 효율 벤치마크 우위는 DeepSeek가 글로벌 응용 산업에서 매출을 만들 수 있는 진짜 차별화 포인트야.
글로벌 응용 산업(특히 동남아·인도·라틴아메리카·아프리카·중동)에는 'GPT-5.4 mini 동급 능력 + 절반 단가' 모델이 매력적이야. 미국 프런티어 모델이 비싸서 도입 어려운 신흥 시장에 DeepSeek V4 Pro가 진입할 가능성이 커. 또 open-weight이라 self-hosted 옵션이 가능해서 데이터 주권 우려 있는 국가·기업에 우선 선택지가 돼.
오픈소스 LLM 생태계에는 큰 이득. DeepSeek V4 Pro 가중치가 공개되면 (또는 곧 공개될 가능성) 학계·인디 개발자가 실제로 다룰 수 있는 GPT-5 급 모델이 생겨. fine-tuning·distillation·specialization 응용이 폭발할 가능성이 있어 — 2024년 Llama 3가 그랬던 것처럼.
과거 유사 사례 — 성공과 실패
성공 사례 1번: DeepSeek V3 ramp (2024-12 → 2025-03). DeepSeek V3가 12월 출시 후 3개월 만에 글로벌 LLM 사용량 지표에서 톱 5에 진입했고, 글로벌 응용 스타트업의 fine-tuning 베이스로 가장 인기가 높았어. V4 Pro도 비슷한 ramp을 그릴 가능성이 있어.
성공 사례 2번: Llama 3 (2024년 4월). Meta가 Llama 3를 open-weight으로 공개하면서 글로벌 LLM 응용 산업이 폭발적으로 성장했어. fine-tuning·distillation·specialization 회사 수백 개가 출범했고, GPT-4 대비 능력은 떨어지지만 '비용·자율성·데이터 주권' 측면에서 우위가 있었어. DeepSeek V4 Pro가 Llama 4 출시 지연(예상 2026 4분기) 사이 공백을 메울 가능성이 커.
실패 사례 1번: Mistral Large ramp 한계 (2024-2025). 프랑스 Mistral이 Mistral Large를 출시하면서 'EU 토종 프런티어 모델'을 자처했지만, GPT-4 대비 능력 격차 + 가격 우위 부재로 글로벌 점유율 5% 영역에 머물렀어. DeepSeek V4 Pro가 미국 시장 진입에서 비슷한 구조적 압박(미국 정부 정책·hyperscaler 결정)을 받을 가능성이 있어.
실패 사례 2번: 中 Qwen 시리즈의 글로벌 ramp 한계 (2024-2025). Alibaba Qwen이 open-weight으로 ramp하면서 글로벌 사용량을 늘렸지만, 미국·EU 정부 규제 + 'china 모델 = 데이터 보안 우려' narrative로 미국·EU 시장 점유율이 1-2% 영역에 머물렀어. DeepSeek V4 Pro도 같은 구조적 한계에 부딪칠 가능성이 있어.
경쟁자 카운터 플레이 — 미국 프런티어, 다른 中 랩
미국 프런티어 5사는 두 갈래로 응수해. 첫째 능력 격차 유지 — GPT-6·Claude Opus 5·Gemini 3 ramp으로 8개월 격차를 12개월 이상으로 벌리는 전략. 둘째 비용 효율 추격 — OpenAI gpt-5.4 mini, Claude Haiku 4.5, Gemini 2.5 Flash 같은 비용 효율 모델로 DeepSeek 가격 우위를 좁히는 전략. 두 전략 동시 추진 중이고, 향후 6-12개월이 결과를 가르는 시점이야.
다른 中 랩(Alibaba Qwen·Tencent Hunyuan·Baidu ERNIE·MiniMax·Zhipu)은 DeepSeek V4 Pro의 평가 결과를 자체 모델 ramp의 가속 시그널로 활용해. Alibaba가 Qwen 4 시리즈 출시를 2026 3분기로 앞당길 가능성이 있고, MiniMax는 동영상 생성 영역에서 차별화를 강화하는 중이야.
EU 모델(Mistral·Aleph Alpha)은 DeepSeek V4 Pro 등장으로 차별화가 더 어려워졌어. 'EU 토종 + 데이터 주권'이라는 포지셔닝은 유지되지만, 비용·능력 두 축에서 DeepSeek 대비 우위가 약해졌어. Mistral이 Mistral Large 3 출시(2026 4분기 예상) 후 가격 인하 압박을 받을 가능성이 있어.
오픈소스 진영(Llama·Stability·EleutherAI 등)은 DeepSeek 등장이 오히려 활성화 신호. fine-tuning 베이스로 DeepSeek V4 Pro를 선택하는 회사가 늘어날 거야. Llama 4 출시 지연 사이 공백을 DeepSeek가 채우는 흐름이 단기 트렌드야.
그래서 뭐가 달라지는데 — 개발자·창업자·투자자·일반 사용자
개발자에게는 'GPT-5 급 비용 효율 대안'이 등장한 거야. DeepSeek V4 Pro API를 쓰면 OpenAI GPT-5.4 mini 대비 토큰 단가가 절반 수준이라, 비용 민감한 응용(콘텐츠 생성·classification·요약 등)에서 진짜 매력적이야. 또 open-weight이라 self-hosted로 돌리면 단가가 거의 0에 가까워.
창업자에게는 'AI 응용 스타트업의 모델 선택지가 진짜로 다변화'됐다는 의미. OpenAI·Anthropic·Google 단일 의존이 깨지고, DeepSeek + 미국 프런티어 듀얼 호스팅 전략이 가능해져. 매출 마진이 향후 12개월 안에 5-10%p 개선될 여지가 있어. 단지 미국·EU 정부 조달·금융·헬스케어 영역은 여전히 미국 프런티어가 우위야.
투자자에게는 두 가지 신호. 첫째 'china AI 인프라(자체 GPU·LLM·서비스) 재평가'. DeepSeek 글로벌 등장이 中 AI 산업 전체 재평가의 트리거야. 둘째 '미국 프런티어의 가격 협상력 약화'. OpenAI·Anthropic 등의 ARR 멀티플 조정 압박이 들어가서 향후 12개월 안에 8-10x → 6-7x 영역으로 이동할 가능성이 있어.
일반 사용자에게는 LLM 앱 가격 인하 또는 더 좋은 무료 티어가 직접 효과. DeepSeek API를 쓰는 응용이 늘면서 ChatGPT·Claude·Gemini 등 미국 모델도 가격 인하 또는 무료 티어 확장 압박을 받아. 향후 6-12개월 안에 일반 사용자 LLM 단가가 30-40% 떨어질 여지가 있어.
스테이크
- Wins: Liang Wenfeng (DeepSeek CEO) — '中 최고 모델' + '비용 효율 우위' 美 정부 공식 인정; 글로벌 응용 산업 — 비용 효율 대안 확보; 오픈소스 LLM 생태계 — fine-tuning 베이스 모델 풍부.
- Loses: 미국 프런티어 비용 효율 모델 (GPT-5.4 mini, Claude Haiku 4.5) — 가격 협상력 약화; EU 모델 (Mistral·Aleph) — 차별화 약화; 中 다른 랩 (Alibaba·Tencent·Baidu) — DeepSeek 단일 우위 우려.
- Watching: 미국 정부 (BIS·상무부) — 中 수출 통제 강화 또는 완화 조정; 신흥 시장 (인도·동남아·중동) — DeepSeek 도입 가속 여부; 학계·오픈소스 — DeepSeek V4 Pro 가중치 공개 시점·라이선스.
반대 의견 — '8개월 격차는 부정확'
Andrej Karpathy (전 OpenAI·Tesla) 같은 학계·인디 연구자는 "8개월 격차 측정은 임의적이고 영역별 격차 분포를 가린다"고 지적해 왔어. 사이버·수학에서는 6-9개월 격차지만 ARC-AGI-2 추상추론에서는 12-18개월 격차라는 게 영역마다 큰 차이가 있는데, 단일 숫자로 압축하면 정책 결정에서 오해를 만들 수 있다는 거지.
Jim Fan (NVIDIA) 같은 업계 전문가는 'DeepSeek V4 Pro가 GPT-5 학습 데이터 distillation 가능성'을 지적했어. 즉 DeepSeek가 GPT-5 출력을 학습 데이터로 흡수해서 GPT-5 급 성능을 빠르게 따라잡았을 가능성이 있고, 그게 '8개월 격차'의 진짜 원인이라는 거야. 자체 R&D 능력의 격차는 12-18개월 영역일 가능성이 더 높다는 시각이야.
회의론은 두 갈래로 정리돼. 첫째 '단일 격차 숫자로 영역별 분포 가림'. 둘째 'distillation 가능성 = 자체 R&D 능력 측정 어려움'. 두 변수 모두 'CAISI 평가가 진짜 능력 격차를 정확히 측정하지 못한다'는 비판으로 수렴해.
3줄 요약
- CAISI 평가에서 DeepSeek V4 Pro가 GPT-5 급 성능, 미국 프런티어 대비 ~8개월 뒤짐 (5월 3일 발간).
- 5개 영역 9개 벤치마크에서 中 최고 모델, 7개 비용 효율 벤치마크 중 5개에서 GPT-5.4 mini 우위.
- 글로벌 응용 산업(특히 신흥 시장)에 비용 효율 대안 등장, 미국 프런티어 가격 협상력 약화 압박.
참고 자료
- CAISI evaluation of DeepSeek V4 Pro — NIST
- DeepSeek V4 trails US frontier by eight months — DigWatch
- Techmeme: CAISI says DeepSeek V4 Pro lags US AI by ~8 months
다음 분기 관전 포인트
DeepSeek V4 Pro의 글로벌 ramp이 어디까지 가는지는 변수 세 가지에 달려 있어. 첫째 가중치 공개 시점·라이선스 — V3와 동일한 MIT 또는 Apache 2.0 같은 관대한 라이선스가 적용되면 학계·인디 응용이 폭발할 거야. 둘째 미국·EU 정부 조달 진입 가능성 — 현재 'china 모델 = 데이터 보안 우려' narrative로 막혀 있는데, EU AI Act 시행 단계에서 self-hosted 옵션이 인정되면 EU 정부 조달도 일부 채널이 열릴 가능성이 있어. 셋째 V5 출시 시점 — DeepSeek가 V5를 2026 4분기에 출시하면 미국 프런티어 격차를 6개월 영역으로 좁힐 수 있고, 동시 출시되는 GPT-6·Claude Opus 6와의 비교가 글로벌 시장 인식을 결정해. 이 세 변수의 다음 6-12개월 진척이 '中 AI 글로벌 진입 = 일회성 vs 지속'을 가르는 변수야.
출처
관련 기사


AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.