China's GLM 5.2 Beat Claude in Semgrep's Security Benchmark — and Reignited the Export-Control Fight
Open-weight GLM 5.2 hit 39% F1 on IDOR vulnerability detection vs Claude Code's 32% — and did it cheaper, at ~$0.17 per finding. While the U.S. tightens controls citing security capabilities, China gave away something comparable for free.

A free Chinese model found security bugs as well as a restricted American one
Here's the deal: code-security firm Semgrep ran its own cybersecurity benchmark, and Zhipu AI's open-weight GLM 5.2 beat Anthropic's Claude Code. On detecting a vulnerability class called IDOR, GLM 5.2 scored 39% F1 versus Claude Code's 32% — a seven-point gap. And it was cheaper, finding each bug for about $0.17.
If that were just "a model won a benchmark," it wouldn't be top news. The reason it exploded is different. GLM 5.2 ships its weights under an MIT license — anyone can download it and run it on their own servers. Meanwhile, the U.S. has been tightening exports of frontier models on the grounds of exactly this kind of security capability. The capability Washington wanted to contain just got handed out for free by a Chinese lab.
That's why Semgrep's title landed so hard — "We Have Mythos at Home," riffing on the meme about the cheap lookalike your parents buy instead of the brand-name thing. On June 28 the post hit #1 on Hacker News (1,056 points, 494 comments), and the thread filled with one question: do export controls even mean anything here? TechTimes ran a piece titled "AI Export Controls Fail Their First Real Test."
So here's today's story: what GLM 5.2 actually did, why Semgrep ran the test, how it spilled into a policy fight, and what changes for security teams, developers, and policymakers. Three players: Zhipu AI, which built the model; Semgrep, which ran the benchmark; and Anthropic, which has the most to lose from the framing.
The players — Zhipu, Semgrep, and the Claude it was measured against
Zhipu AI is one of China's flagship LLM startups, with roots in Tsinghua University. Its GLM series sits alongside Alibaba's Qwen and DeepSeek as China's open-weight powerhouses. GLM 5.2 went to paid "GLM Coding Plan" members on June 13, with open weights following three days later on June 16. Architecturally it's a Mixture-of-Experts model with roughly 750 billion total parameters but only about 40 billion active per token — big, but cheap to run — and it stretches context from 200K up to 1M tokens.
Semgrep builds static analysis tooling that flags security vulnerabilities in code. It's well known among developers, and lately it has been publishing its own benchmark that ranks frontier models on security tasks. The key fact: Semgrep doesn't sell a model. It has no reason to root for a Chinese one. If anything, its incentive is to show that its own multimodal pipeline (53–61% F1) beats any single model. That neutrality is what gave the result weight.
Anthropic's Claude shows up as the comparison — and the loser here. But keep perspective: this is one narrow vulnerability class (IDOR), inside one specific Semgrep prompt and harness. It says nothing about Claude's overall coding or security ability. The reason a single line went viral is that the U.S. has been restricting exports over precisely this capability. The symbolism outran the numbers.
Tie it together: a free, open-weight model from a Chinese startup beat an American frontier model, on a neutral firm's test, at the very capability Washington most wanted to contain. That's the spine of it.
What actually happened — by the numbers
Start with IDOR (Insecure Direct Object Reference). In plain terms: "I bumped the order number in the URL by one and saw someone else's order." It's an authorization-bypass bug that's hard to catch from code alone, because you have to understand who's allowed to access what — as context. It's one of the weakest spots for static tools, and a real test of whether an LLM can read code flow the way a human reviewer would.
| Metric | GLM 5.2 | Claude Code | Semgrep multimodal pipeline |
|---|---|---|---|
| IDOR F1 score | 39% | 32% | 53–61% |
| Cost per finding | ~$0.17 | Higher | Separate harness |
| Weights | Open (MIT) | Closed | N/A |
| Context window | Up to 1M tokens | Varies | N/A |
Two things stand out. First, among single models, GLM beat Claude. Second, both still trailed Semgrep's purpose-built pipeline (53–61%) by a wide margin. So "drop in an LLM and security automation is solved" is not the takeaway. A well-designed harness still wins. That may be the real message Semgrep wanted to send: models keep improving, but our pipeline still earns its keep.
GLM still grabbed the headline, and the reason is simple. 39% vs 32% looks small, but "free open model ≥ closed frontier model" was confirmed for the first time in a sensitive domain like security. Add the cost edge — $0.17 per finding — and in real security-automation work, where you scan code at massive scale, economics drive adoption. If something is roughly as good and ten times cheaper, people use it.
Who wins, who's uncomfortable
Zhipu AI won biggest. It bought, with one neutral benchmark, trust that $100M in marketing couldn't. It rebutted the "Chinese open models are benchmark-gamed" suspicion head-on, and earned a credible reference in a conservative buyer market. Because the weights are open, enterprises can run it on their own servers without sending data out — a real draw for security teams.
Semgrep comes out fine too. It sells no model, so it doesn't care who wins, and it reinforced its position as the neutral referee of model competition — while also showing its own pipeline beats any single model. One post, both credibility and pipeline marketing.
The uncomfortable parties are Anthropic and U.S. export-control policy. For Anthropic it's one line on a narrow test, but it collided with its own security-strength narrative. The policy side hurts more. The logic of control is "stop dangerous capability from reaching rivals" — but if the rival publishes that capability for free, the premise wobbles. The "you can block the front door, it leaves through the side" critique gets harder to answer.
Precedents — what worked and what didn't
We've seen this movie. DeepSeek is the obvious one. In early 2025, a Chinese open model reportedly matched U.S. frontier-grade reasoning at far lower cost, and markets shook. The narrative then — "block the chips, they'll catch up on efficiency" — is the same one GLM 5.2 just extended from reasoning to security.
There are successful controls too. Physical bottlenecks like cutting-edge EUV lithography held up well. When a single machine costs hundreds of millions and only a few firms can build one, gatekeeping works. But software and model weights are different in kind: once they're on the internet, the cost to copy is effectively zero. There's no chokepoint to guard. That's the decisive difference between hardware and software controls.
The failure lesson is just as clear. Look at crypto export controls. In the 1990s the U.S. classified strong encryption as a "munition" and restricted exports — until the code spread via books, T-shirts, and overseas servers, controls went hollow, and the policy eventually relaxed. A classic case of how hard it is to stop a digitally copyable capability at the border. The GLM episode reads like the AI sequel.
Competitor counter-plays
The counter for frontier labs like Anthropic and OpenAI isn't a benchmark line — it's the whole system. Single-model scores can be matched, but the package of safety guardrails, agent harnesses, enterprise integration, and accountability is hard to clone from open weights alone. Just as Semgrep showed its pipeline beats any single model, the natural move is to reframe: "the model is a component; the system is the value."
U.S. policymakers face a fork. One path is tighter control — but with no chokepoint for weights, efficacy is doubtful. The other is "lead instead of contain" — build the better thing faster and set the standard. This episode strengthened the second camp's argument: spend the energy on staying ahead, not on a fence that doesn't hold.
Other Chinese labs (Alibaba Qwen, DeepSeek) will ride the wave. Open-weight releases just got reconfirmed as a fast route to global trust and adoption — especially in security and coding, where enterprises want to run things on their own infrastructure. The closed-frontier camp is being pushed to answer, more sharply, not just "are we better?" but "why should you pay us?"
So what changes
If you run security — you have more options. For cost-dominated work like scanning code at scale, open-weight models are now a real card. But remember: an IDOR F1 of 39% means you miss more than half. No model is enough alone; as Semgrep's data shows, it pays its way inside a dedicated pipeline. Harness design matters more than model swapping — that's the operational lesson.
If you build software — running open-weight models in your own environment keeps getting more reasonable: no data leaving, cost under control, fine-tuning possible. GLM 5.2's 1M-token context is handy for reading large codebases in one pass. Just verify the license (MIT), real operating costs, and your domain's performance yourself.
If you follow policy — this will be cited for a while as a textbook case of export-control limits. The core question: can you stop a zero-copy-cost capability at the border? Hardware (chips, tools) has chokepoints, so control works; model weights don't. Expect the debate to shift from "what do we control and how" to "how do we tell controllable domains from uncontrollable ones."
🥄 Three Things You're Probably Wondering
— So is Claude just worse than GLM now? No — don't read it that way. This compared one vulnerability class (IDOR) inside one specific Semgrep test. It says nothing about overall coding, reasoning, or safety. Think one narrow track, one race.
— So should security teams just deploy GLM 5.2 and call it done? Too early to say. An F1 of 39% means missing more than half, and Semgrep's own pipeline (53–61%) still did better. The real message is that a model inside a well-designed system beats a model alone.
— Are export controls pointless now? Hardware controls still bite — chips and tools are hard to make and have clear chokepoints. What this exposed is that weights, with zero copy cost, are structurally hard to stop. Not "all pointless," but "it depends on the domain."
References
- We Have Mythos at Home: GLM 5.2 beats Claude in our Cyber Benchmarks — Semgrep
- GLM-5.2 Tops Claude Code in Semgrep IDOR Benchmark — WinBuzzer
- GLM 5.2 Outperforms Claude Code on Semgrep's IDOR Benchmarks — Developers Digest
- AI Export Controls Fail Their First Real Test — TechTimes
- China's New Zhipu AI Matches Claude in Vulnerability Detection — CybersecurityNews
Numbers and criteria are as of announcement and may change.
출처
관련 기사
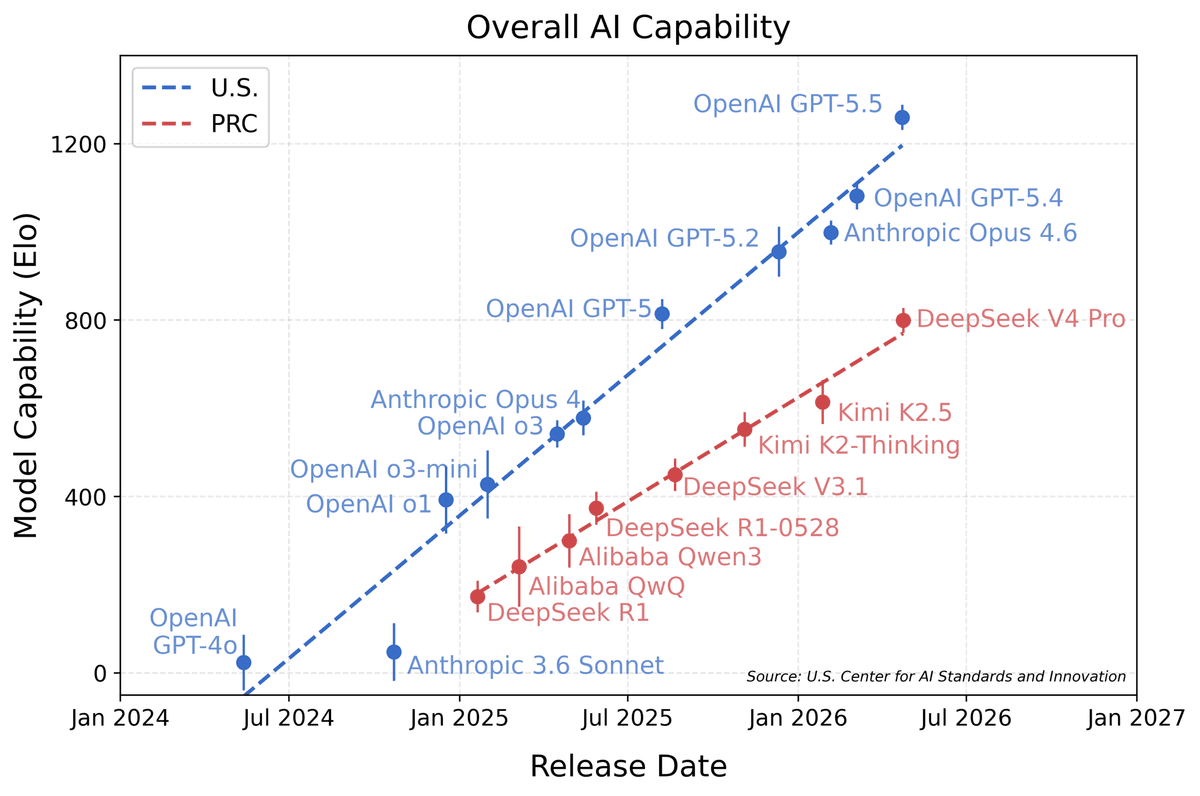
CAISI: DeepSeek V4 Pro Lags U.S. Frontier by ~8 Months, Still Most Capable PRC Model

The Mythos 5 Model the U.S. Killed Two Weeks Ago Is Back — But Only for 100 Companies
GPT-5.4 hits OSWorld-V 75% — autonomy goes mainstream
AI 트렌드를 앞서가세요
매일 아침, 엄선된 AI 뉴스를 받아보세요. 스팸 없음. 언제든 구독 취소.