Here's the deal: the "limited-time" 75% just quietly became the new list price
DeepSeek locked in the 75% discount on its flagship V4-Pro as a permanent price cut. That discount was originally a limited promo set to expire on May 31. Then, around May 22–23, DeepSeek declared the discounted price the new list price, and Bloomberg, Engadget and InfoWorld all reported it between May 23 and 25. A flash sale just turned into a structural price reset.
The numbers make it stark. V4-Pro now costs roughly $0.435/M input (cache miss), $0.003625/M cache hit and $0.87/M output. Against the old $0.0145–$3.48 range, that's about a quarter of the price. On output tokens, compared with Western frontier models like GPT-5 or the just-released Gemini 3.5 Flash, you can run the same job for a fraction of the cost.
The timing matters. V4 (Pro 1.6T, Flash 284B, 1M context) launched in preview just a month earlier, on April 24. New models usually protect margin early; DeepSeek did the opposite. One month in, it chose share over unit revenue — willing to forgo per-token profit to pull developers and enterprises into its ecosystem.
And this is more than "cheap Chinese model." The V4 family is DeepSeek's first optimized for Huawei's Ascend accelerators. With U.S. controls on advanced GPUs to China tightening, the combo of "domestic chips + cheap inference" actually working is the real center of gravity here.
The players — DeepSeek, Huawei Ascend, and the Western frontier
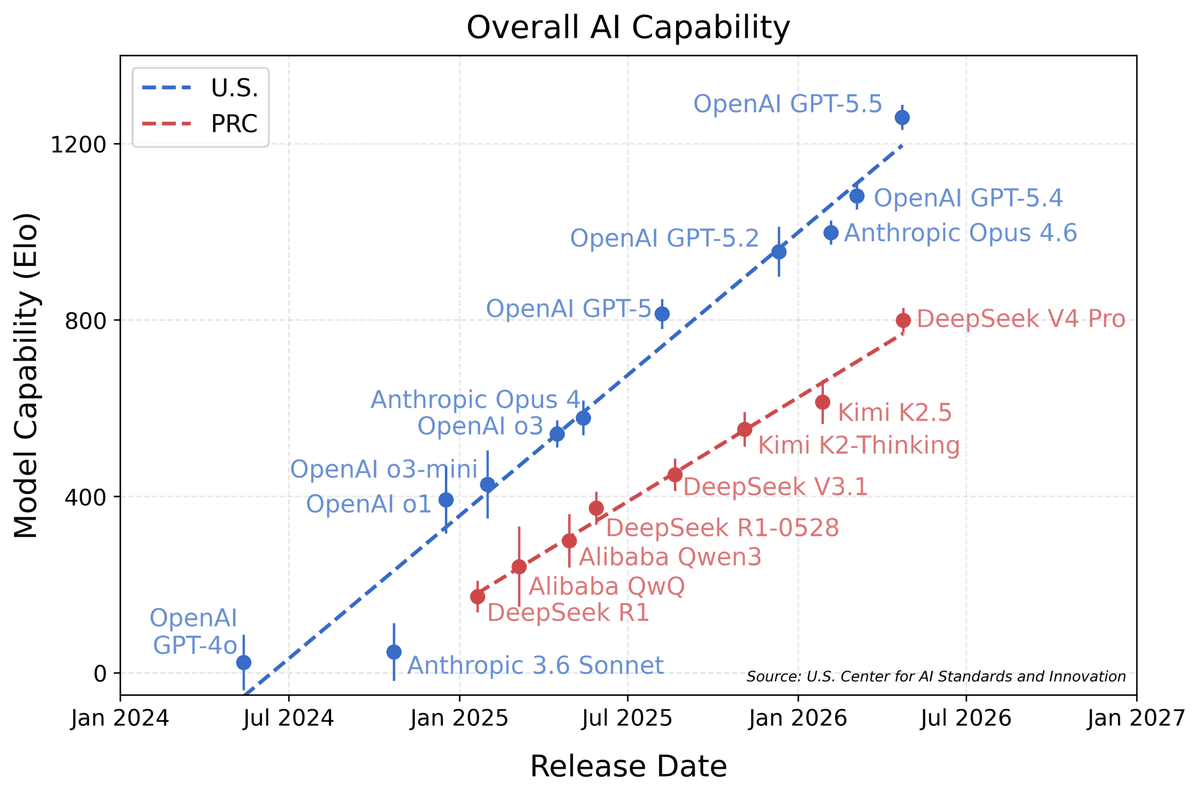
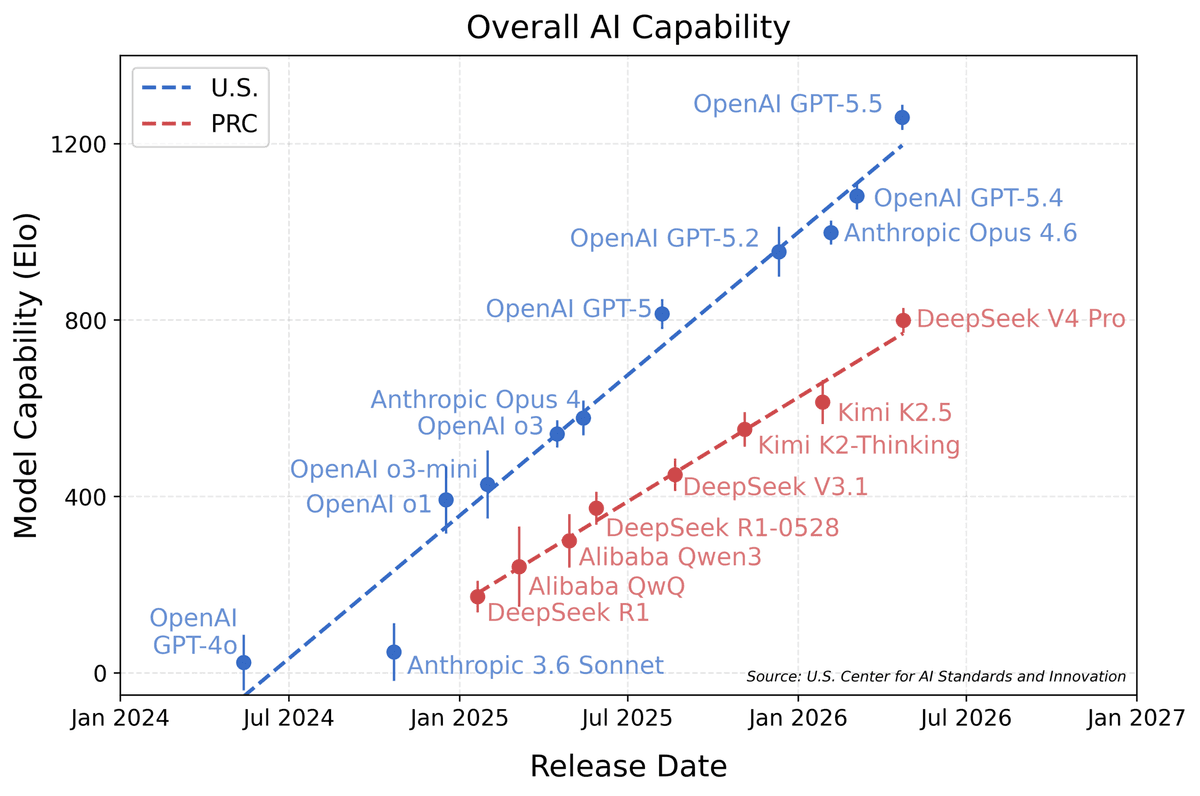
DeepSeek. The Chinese lab that became shorthand for "low-cost reasoning" with R1 in early 2025. This permanent cut reinforces that identity. DeepSeek's strategy is consistent — use open weights and aggressive pricing to fight the Western labs on the cost axis. Even with a frontier-performance gap, it owns the "good enough, dramatically cheaper" position.
Huawei Ascend. The hidden protagonist. Per reporting, rising availability of Ascend 950 and 950PR supernode systems is what gives DeepSeek the confidence to sustain low pricing. It means large-scale inference infrastructure that doesn't depend on NVIDIA H100/H200 is maturing inside China — U.S. sanctions paradoxically catalyzing a domestic AI-silicon stack.
The Western frontier (OpenAI, Google, Anthropic). They hold the performance edge with GPT-5, Gemini 3.5 and Claude. But permanent low pricing pressures their margins and price ladders — especially in agentic, coding and high-volume workloads where "inference cost = business viability," and customers start asking whether the performance delta justifies the price delta.
What got cheaper, and by how much
What changed. The 75% discount, due to expire May 31, became indefinite. The key is that the word "temporary" is gone. The scariest thing about building on V4-Pro was "costs spike when the discount ends" — that uncertainty is now removed. Low pricing is the default, not a bargaining chip.
The price structure. $0.435/M input (cache miss), $0.003625/M cache hit, $0.87/M output. Cache hits at $0.003625 are extreme. For RAG and agent workflows with lots of repeated context, real-world cost drops even further. Running 1M context at this rate means "stuff the whole document in" can become routine without budget pain.
The infrastructure backdrop. V4 is the first Ascend-optimized family, and the expanding Ascend 950/950PR supernodes are cited as the foundation. So this is likely "the cost base actually dropped," not "a loss-leading marketing sale." If true, it's much harder for Western labs to match — they still run on expensive NVIDIA GPUs.
| Item | V4-Pro (after permanent cut) | Prior price / comparison |
|---|---|---|
| Input (cache miss) | ~$0.435 / 1M | ~1/4 of prior top |
| Cache hit | $0.003625 / 1M | extreme edge on repeated context |
| Output | $0.87 / 1M | ~1/4 of prior $3.48 |
| Context | 1M tokens | V4 Pro 1.6T params |
| Discount type | Permanent (now list price) | was temp, expiring 5/31 |
Competitive position. DeepSeek isn't chasing the #1 benchmark. It's redefining the market on price-performance. Even if GPT-5 and Gemini 3.5 Flash lead on quality, "DeepSeek is good enough and far cheaper" becomes a powerful option for bulk, repetitive work.
What each side gets out of it
DeepSeek. The most direct winner. It grows share fast and lays the groundwork to lock developers and enterprises into its API. Per-token revenue falls, but at scale the bigger assets — data, feedback, ecosystem — compound. Classic "cheap → share → ecosystem moat" platform playbook.
Huawei. Ascend gets a reference that it can handle large-scale inference in production. If DeepSeek's low pricing is provably enabled by Ascend, other Chinese labs and government projects pile onto Ascend too. It's commercial proof of an "AI self-sufficiency stack" that runs without U.S. GPUs.
China's AI ecosystem. Cheap inference is a fuel-cost cut for domestic startups and app developers. They can ship more AI products, more cheaply — a foundation for an explosion of domestic AI applications.
Who loses. Western frontier labs' margins and pricing get squeezed, especially the "cheap flash-tier for the mass market" camp (Gemini Flash, GPT mini). And the dispute over DeepSeek's training data provenance (Anthropic's past "distillation" concerns) has fresh kindling.
Precedents — successes and failures
The DeepSeek R1 shock (early 2025). This isn't DeepSeek's first time rattling the market with low-cost reasoning. R1 proved "similar performance at far lower cost" and even rocked NVIDIA's stock. This permanent cut is Act II — not a one-off shock, but an attempt to entrench sustainable low pricing.
Cloud price wars (AWS/GCP/Azure). Infrastructure markets repeat the spiral of "cut price → grow share → economies of scale → cut again." The winners actually lowered their cost base; the ones doing "marketing loss sales" eventually retreated. Which one DeepSeek is depends on whether Ascend economics are genuinely low — and if Ascend-based, likely the former.
The trap of reckless discounting. There's a counter-case too. Firms that chased share with prices unsupported by a cost advantage burned cash and collapsed. DeepSeek's fate hinges on whether Ascend's cost is truly low enough. If the pricing leans on subsidies and losses, this war won't last.
Competitor counter-plays
OpenAI / Google. They could match with cuts, or sidestep via "performance, trust, ecosystem" differentiation. The latter is more likely — beating Chinese Ascend economics on raw price is hard, so they'll defend a premium on "GPT/Gemini are smarter, safer, better integrated," while perhaps trimming flash/mini tiers.
Anthropic. Differentiates on safety, trust and enterprise governance rather than price. But if DeepSeek's cheapness eats into the coding/agent market, products like Claude Code feel pricing pressure too. Anthropic could revive its "distillation" concerns to frame DeepSeek as a "provenance-unclear cheap model."
NVIDIA. The most delicate spot. The more DeepSeek's pricing is enabled by Ascend, the narrower NVIDIA's footing in China. NVIDIA will argue "inference demand is exploding, so the whole pie grows," but the rise of an Ascend alternative is a long-term risk.
Western open-weight camp (Meta Llama, etc.). Most directly exposed to DeepSeek's "open + cheap" combo. Strong incentive to differentiate Llama not on price but on on-prem, customization and licensing.
So what actually changes — by persona
AI developers / startups. Inference costs dropped another notch. For token-heavy products (bulk processing, agents, RAG), seriously consider V4-Pro to slash unit costs. But weigh data governance and geopolitical risk (dependence on a Chinese API). "Cheap" isn't everything.
Enterprise IT / procurement. Your leverage just grew. Use "V4-Pro is at this price" to negotiate other vendors down. Many orgs can't use Chinese models directly for regulatory/data-sovereignty reasons, so the realistic move is wielding it as a benchmark pressure card.
Investors. It's clearer that AI inference is a market with simultaneous "margin compression + scale competition." Decide whether you're betting on frontier performance or cost advantage (chips, infra). The rise of the Huawei Ascend stack reshapes semiconductor investing too.
Policy / security folks. The paradox of "U.S. GPU controls → Chinese Ascend self-sufficiency" is materializing. Sanctions may work short-term, but the side effect of nurturing a domestic alternative stack needs reassessment.
Everyday users. Little direct impact now, but it's one scene in the broader story of AI getting cheaper to run. More apps embed AI more cheaply, and AI seeps deeper into daily life.
Further reading
- InfoWorld — DeepSeek's steep V4-Pro price cut escalates AI pricing war
- Engadget — DeepSeek permanently reduces the price of its flagship V4 model by 75 percent
- Bloomberg — DeepSeek To Make Permanent 75% Discount on Flagship AI Model
- The Next Web — DeepSeek made its 75% discount permanent. The AI price war just escalated
- Dataconomy — DeepSeek Slashes V4 Pro Price By 75%